8 min de lecture
Collecter le temps des demandes de milliers d'applications
Découvrez comment nous avons rassemblé des milliers de métriques en utilisant une seule instance InfluxDB avec seulement quelques gigaoctets de RAM.

Lorsque nous avons publié le panneau des Metrics sur le tableau de bord de Scalingo il y a plus d'un an, nous voulions donner le plus d'informations possible aux développeurs concernant les performances de leurs applications. Pour vous aider dans cette tâche, nous venons d'ajouter à ce panneau la durée des requêtes de l'application. Cet article explique comment nous avons recueilli un grand nombre de métriques en utilisant une seule instance InfluxDB avec seulement quelques gigaoctets de RAM.
Lors de la maintenance d'une application, un développeur s'intéresse à quelques métriques pour détecter les goulets d'étranglement ou les problèmes de performance. Le tableau de bord de Scalingo a été amélioré il y a plus d'un an avec une vue des métriques pour aider les développeurs à comprendre le comportement de leurs applications en production. Mais une métrique manquante était le temps des requêtes, qui pourrait être intéressant dans le processus de maintenance de l'application.
Voici à quoi cela ressemble sur votre tableau de bord :
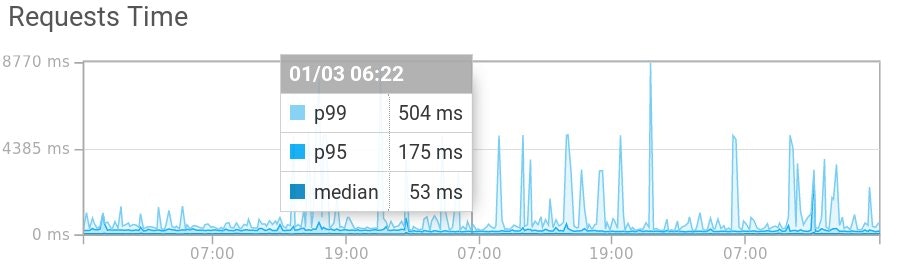
La médiane des temps de requêtes ainsi que les 95e et 99e percentiles (p95 et p99) sont affichés pour mieux comprendre la distribution, les valeurs aberrantes des temps de vos requêtes. D'après Wikipedia, un percentile est :
la valeur en dessous de laquelle un pourcentage donné d'observations dans un groupe d'observations tombe.
Plus précisément, nous comprenons d'après l'exemple ci-dessus que 95 % des temps de requêtes sont de 175 ms ou moins et que 99 % des temps de requêtes sont de 504 ms ou moins. Ce que nous appelons la médiane est en fait le 50e percentile. Ainsi, dans cet exemple, 50 % des temps de requêtes de notre application sont de 53 ms ou moins.
Comment ça marche ?
Rassembler des métriques pour des milliers de requêtes par minute, pour des milliers d'applications nécessite de réfléchir soigneusement à l'architecture. Scalingo gère actuellement environ 20 000 requêtes par minute et cela ne cesse de croître. Stocker la durée de toutes ces requêtes nécessiterait beaucoup de RAM ! Voici comment nous contourner cela, en utilisant notre stack de métriques.
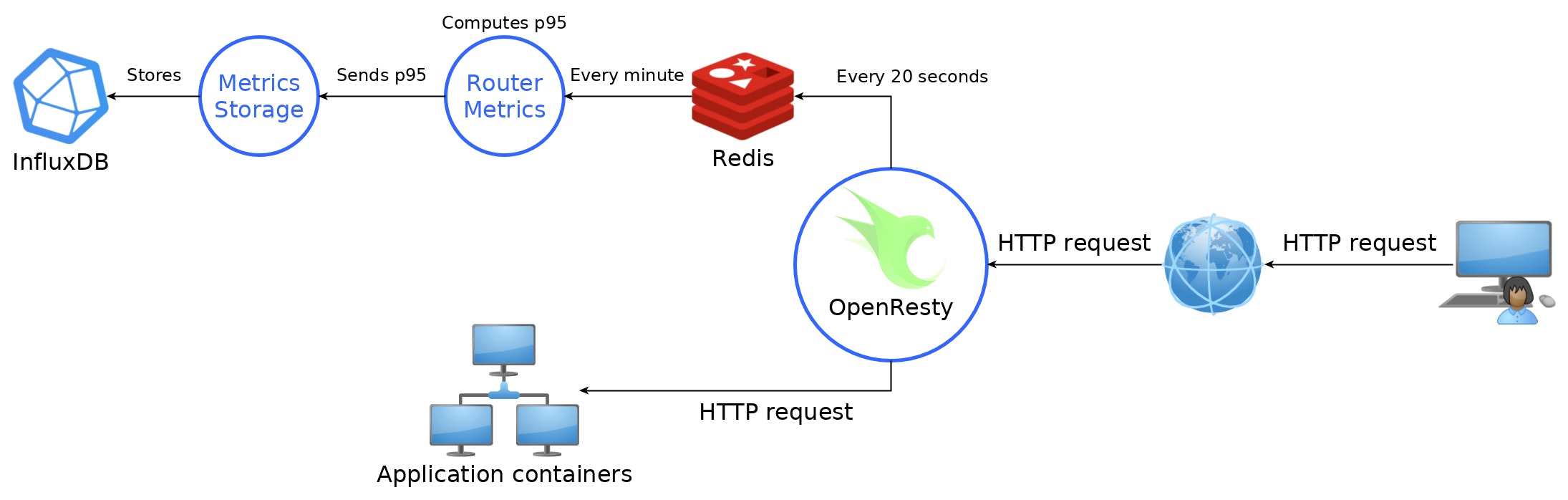
Cette image représente l'architecture de notre stack de métriques. OpenResty est le proxy inverse, point d'entrée de toutes les applications hébergées. C'est donc l'endroit idéal pour calculer la durée de chaque requête. Chaque fois qu'une requête atteint OpenResty, nous créons un nouveau thread léger Lua pour gérer l'enregistrement des métriques.
Ces durées sont stockées dans la RAM d'OpenResty dans une table de hachage associant un ID d'application à une liste de temps de requêtes. Ce hachage est vidé toutes les 20 secondes dans une base de données Redis.
Ensuite, chaque minute, le service metrics router lit les données dans Redis et calcule la médiane, le 95e percentile et le 99e percentile pour les envoyer au service metrics storage.
Le service metrics storage est chargé de stocker les données dans une base de données de séries temporelles. Ce service a été créé pour que nous ne dépensions pas sur un unique fournisseur de base de données de séries temporelles. InfluxDB est actuellement en utilisation mais tout autre type de base de données de séries temporelles pourrait être facilement mis en œuvre.
Cette astuce nous permet de stocker 3 points de données par application par minute dans InfluxDB, quel que soit l'intensité du trafic. Une telle charge devrait être facilement gérée par InfluxDB.
Impact sur l'infrastructure
Bien que nous ayons pris grand soin de concevoir cette stack de métriques, nous voulons nous assurer que la collecte des temps de requêtes n'impactera pas l'infrastructure : ni OpenResty avec le morceau de code qui envoie les temps de requêtes à Redis, ni les autres services, y compris la base de données InfluxDB.
Pour mesurer l'impact sur les performances, nous avons surveillé la consommation de RAM et de CPU d'OpenResty, du router metrics et des services de stockage des métriques. Un scénario en trois étapes a été employé pour valider notre approche. Chaque étape doit être validée avant de déclencher l'étape suivante.
Déployez la même application deux fois. Les temps de requête pour une application sont collectés, et pas pour l'autre. Les deux applications sont interrogées avec 150 requêtes par seconde pendant 5 minutes. Aucun impact sur aucun service ou base de données n'est perceptible.
Les temps de requête pour tous nos services hébergés sur Scalingo sont collectés. Ci-dessous figure le graphique pour notre API :
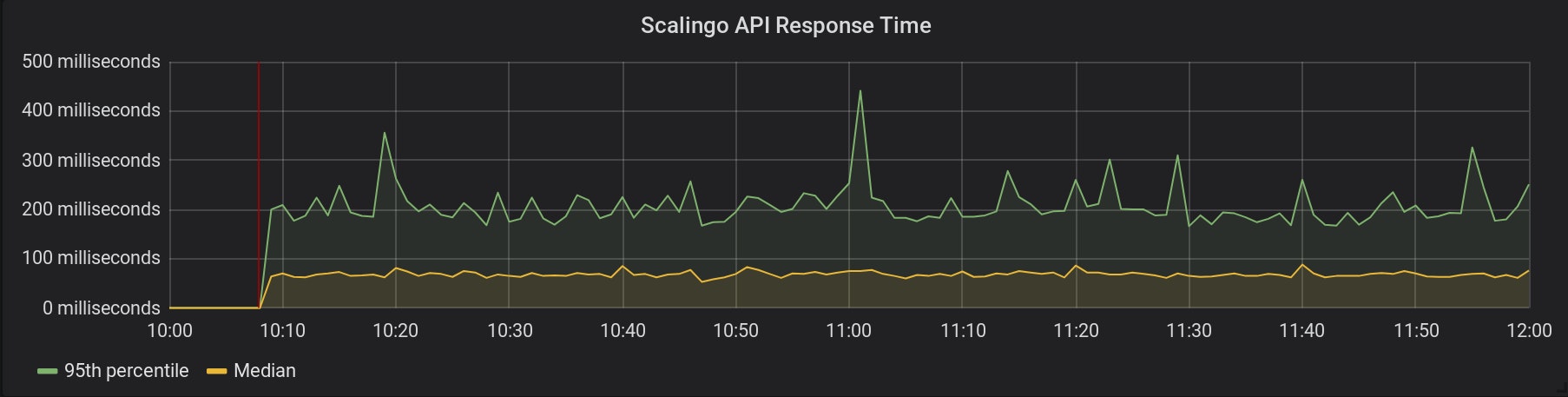
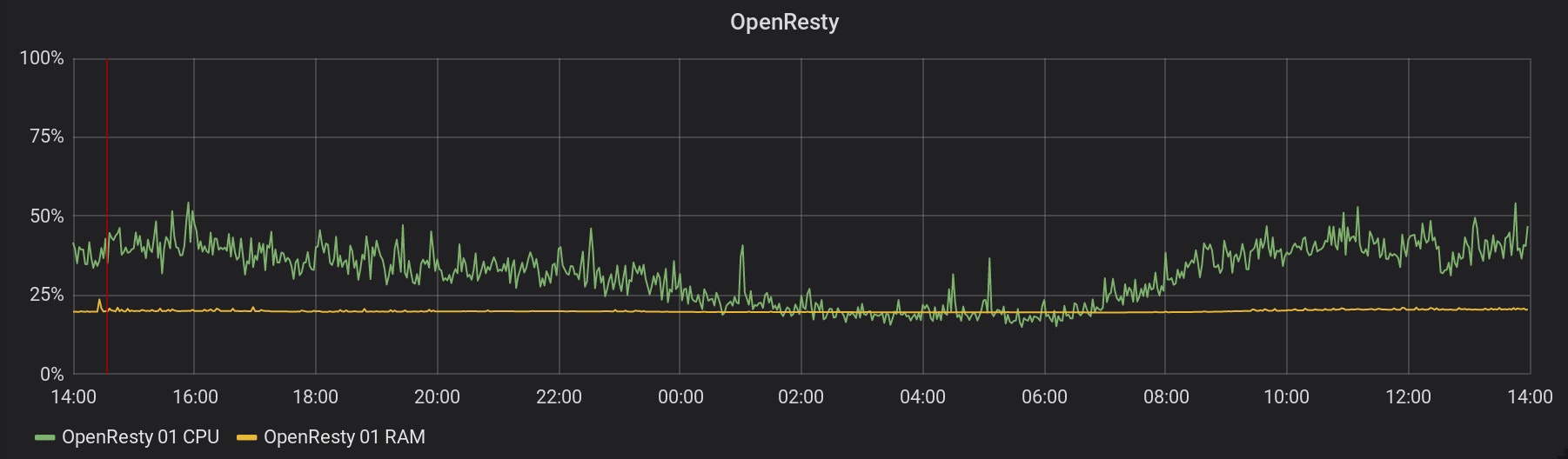
La collecte de métriques a commencé à 10h08 (représenté par la ligne rouge). Voici un graphique de la consommation de CPU et de RAM de l'une de nos instances OpenResty, pendant la même période :
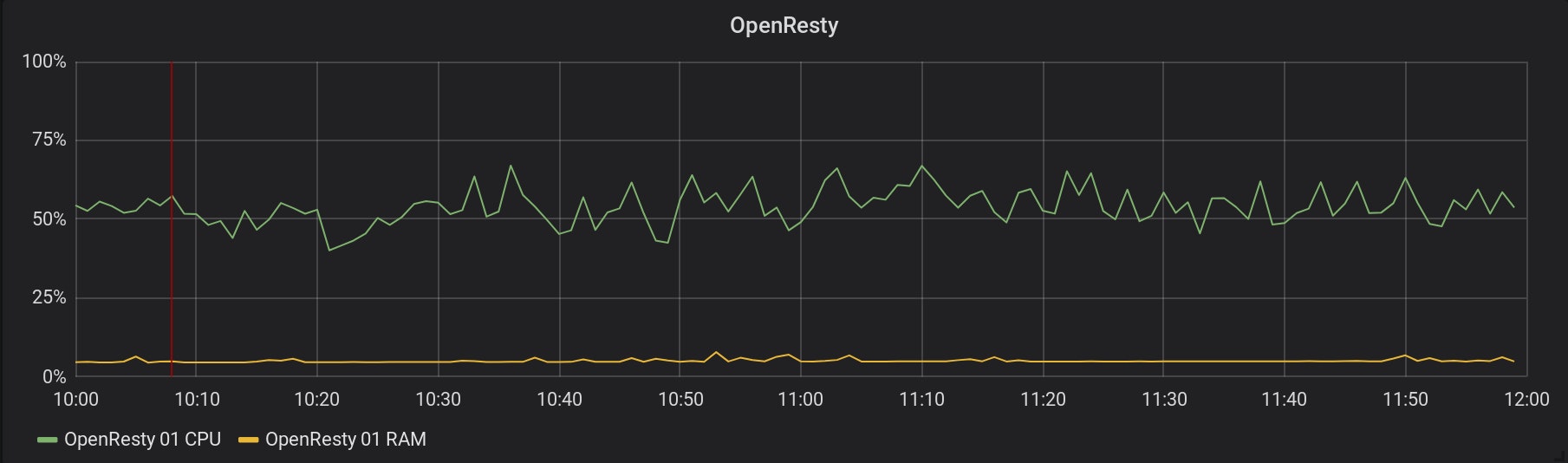
Les graphiques pour tous les OpenResty en fonctionnement ressemblent au même. Ces serveurs ne semblent pas souffrir de cette collecte de métriques ! Et c'est la même chose pour tous les services et bases de données impliqués. 3. Les temps de requête pour toutes les applications sur Scalingo sont collectés à partir du 22 février à 14h32 (représenté par la ligne rouge). Trouvez ci-dessous les graphiques de l'impact sur deux des services de la stack de métriques :
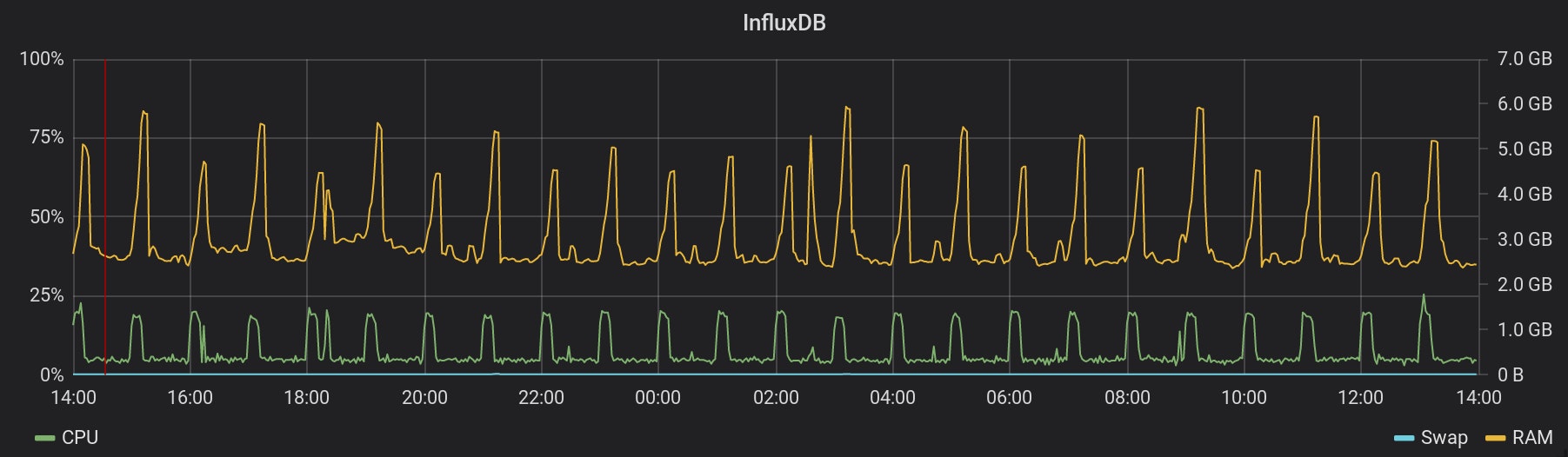
Une fois de plus, il semble que notre infrastructure gère facilement cette charge supplémentaire.
Avec cette nouvelle métrique collectée par la plateforme, nous développons deux nouvelles fonctionnalités qui pourraient être très utiles pour surveiller votre application. Une façon de déclencher une alerte chaque fois qu'une de vos métriques d'application dépasse un certain seuil. Un service d'autoscaling, capable de faire évoluer vers le haut ou vers le bas une application en fonction de ses besoins, est également en cours de développement dans le jardin de Scalingo.
Restez à l'écoute !
Photo de couverture par [Mitchel Boot](https://unsplash.com/photos/hOf9BaYUN88) sur [Unsplash](https://unsplash.com/)

Étienne Michon
Docteur en informatique, Étienne Michon occupe actuellement le poste d'ingénieur R&D chez Scalingo. Il était l'un des premiers employés de Scalingo et il contribue grandement à faire grandir ce blog grâce à ses articles techniques de qualité.
Restez informé
Recevez des articles et des mises à jour de la plateforme dans votre boîte de réception.
Prêt à déployer en toute confiance ?
Découvrez des déploiements sans temps d'arrêt, une mise à l'échelle automatique intelligente et une infrastructure entièrement gérée. Commencez à déployer vos applications sur Scalingo dès aujourd'hui.
Aucune carte de crédit requise • Déployez en quelques minutes • Annulez à tout moment






