10 min de lecture
De 0 à 600 transactions par seconde en 4 jours
Ou la folle histoire du déploiement de la plateforme jeveuxaider.gouv.fr annoncée dimanche 22 mars par le secrétaire d’État Gabriel Attal puis par le Président de la République Emmanuel Macron.

Ou la folle histoire du déploiement de la plateforme jeveuxaider.gouv.fr annoncée dimanche 22 mars par le secrétaire d’État Gabriel Attal puis par le Président de la République Emmanuel Macron.
Contexte & Enjeux
Face à la crise sanitaire liée au covid-19, les milieux associatifs ont besoin de jeunes bénévoles et d’aide puisque 45% des bénévoles ont plus de 65 ans et doivent donc limiter leurs déplacements. Pour accompagner au mieux les associations qui sont en premières lignes dans cette crise, il a été décidé que la plateforme de la Startup d’État Réserve Civique sera le service mis à disposition pour mobiliser des jeunes bénévoles. Cette plateforme devrait donc réceptionner un flux de demande extraordinaire par rapport à son activité actuelle.
Dans le cadre de l’aide que Scalingo a décidé d’apporter aux projets informatiques qui aident à répondre à la crise sanitaire, nous avons proposé nos services à l’équipe de la plateforme Réserve Civique sur les sujets d’infrastructure pour améliorer au maximum la robustesse de la plateforme d’ici à l’annonce officielle de la mesure de solidarité transgénérationnelle. Dès le départ, nous décidons de nous jeter dans ce projet commando tout en proposant pro bono nos services de setup, d'accompagnement, et de coaching. On propose également de sortir de notre cadre habituel d’assistance pour décharger au maximum l’équipe de développeurs qui va avoir fort à faire dans son travail d’adaptation : on proposera des changements sur la base de code si on estime que ça aide la scalabilité, la déployabilité ou la maintenance future par les développeurs.
J-4 : Branle-bas de combat
Le “business owner” nous indique que dans 4 jours la plateforme sera annoncée lors d’un passage télé de grande audience via une personnalité politique majeure : le Président de la République ou un Secrétaire d’État, rien de moins ! Plusieurs autres passages TV sont d’ailleurs programmés.
La pression est maximale !
Toutes les équipes sont sur le pont :
L’équipe “business” qui doit faire le lien avec les besoins terrain des associations et les missions qu’elles vont proposer et le recrutement de volontaire pour déterminer les fonctionnalités de la plateforme ;
L’équipe de développement qui doit prendre en main une nouvelle base de code et l’adapter aux nouveaux besoins ;
L’équipe “ops” qui doit elle aussi prendre en main la base de code pour éventuellement proposer des modifications facilitant la scalabilité mais surtout qui doit provisionner l’infrastructure nécessaire au déploiement du site ;
L’indisponibilité ou le dysfonctionnement du portail pendant des événements médiatiques communiquerait une image négative sur la gestion du programme malgré un travail exemplaire des acteurs sur le terrain. Il est donc indispensable d’assurer la disponibilité de la plateforme.
Les premières estimations nous montre que la plateforme devra être capable d’encaisser entre 500.000 et 3.000.000 visiteurs uniques en 30 minutes. Les visiteurs pourront être de 2 types : une structure qui a besoin de volontaires, ou un·e volontaire. Dans les deux cas, une création de compte a lieu, afin de mettre en relation les acteurs.
Il faut donc livrer en 4 jours une plateforme pouvant tenir une charge extraordinaire. Le contexte est clair : c’est un projet commando. On le sait, mais on oubliera régulièrement durant les 4 prochains jours ce que ça implique.
Des bras supplémentaires ne seront pas de trop. On prend la décision de demander le renfort de Fabien Arcellier d’OCTO Technology pour conduire les campagnes de test de montée en charge. Nous avions déjà travaillé avec Fabien sur le portail principal d’informations iledefrance-mobilites.fr, un autre site web avec des contraintes fortes de scalabilité.
J-3 : Naissance de l’environnement de pré-production
Premières prises en main de la base de code : c’est un projet basé sur le framework Laravel en version 6. Plus exactement, c’est un projet utilisant Laravel Mix qui sépare bien le back en Laravel et le front en Vue.
Avoir ce genre d’architecture aide beaucoup la scalabilité parce qu’il est très simple de servir le front par un CDN (Content Delivery Network). Ça tombe bien, on a pas mal d’expérience avec Cloudflare et ses multiples possibilités intéressantes dans un contexte où beaucoup de paramètres doivent être contrôlés tels que :
La configuration du WAF (Web Application Firewall) pour bloquer ou afficher un challenge aux utilisateurs ayant un comportement suspect ou dangereux,
La configuration du système de cache pour que Cloudflare ne génère pas les règles de caching automatiquement mais utilise les headers renvoyés par l’application (activation du Origin Cache Control),
La configuration du site pour qu’il répartisse les requêtes sur les deux IP dédiées au projet,
L’activation de la fonctionnalité Always Online qui bascule automatiquement sur une vue crawlé du site ce si ce dernier n’est pas disponible,
Le bannissement de trafic depuis certaines régions géographiques,
L’ajout des edge certificates pour que Cloudflare soit capable d’accepter du trafic HTTPS en utilisant un certificat pré-généré,
L’activation de la redirection HTTP vers HTTPs on edge
À partir de là, on rentre dans du classique pour un PaaS tel que Scalingo : on crée une application sur la plateforme et on la lie au dépôt GitHub utilisé par les développeurs pour activer l’auto-déploiement : à chaque commit sur GitHub, Scalingo écoute les modifications et déploie les nouvelles versions au fil de l’eau. À chaque nouveau commit correspond un nouveau déploiement.
L'application sera hébergée dans notre toute nouvelle région osc-secnum-fr1 qui repose sur le datacenter certifié SecNumCloud de notre partenaire Outscale.
Cependant la base de code n’est pas tout à fait “Cloud Ready”, c’est-à-dire qui suit les principes édictés par 12 Factor. Heureusement Laravel a tout ce qu’il faut en magasin pour “bien se comporter” en environnement cloud. C’est l’affaire d’options et de paramétrage. On propose d’entrée de jeu plusieurs Pull Requests pour améliorer ce comportement :
Configuration depuis l’environnement des variables d’environnement relatives à Passport
Inclusion optionnelle des dépendances de développement comme l’application est déployée en mode “production”
Utilisation du Multi-Buildpack pour d’un côté compiler le code Javascript avec Node.js et de l’autre, exécuter l’application PHP
Automatiquement appliquer les migrations de base de données lors d’une nouvelle mise en production
La pression monte, et c'est le moment du clash des cultures entre l’équipe de développeurs et l’équipe Scalingo qui est habituée à faire ce genre de modifications et les prend pour acquises. C’est donc aussi le moment de quelques frictions dans les communications. Et oui, c’est un projet commando et on a déjà oublié que la communication doit être très explicite dans ce contexte ! Fort heureusement l’intérêt commun prévaudra et tout se calmera. Chez Scalingo on estime que ces moments où ça tangue très fort font partie du process. L’important est de s’en rendre compte rapidement et de modifier ses comportements pour améliorer l’équipe.
La base de données utilisée jusque là par le projet était MySQL. Chez Scalingo on maîtrise très bien PostgreSQL en environnement en forte charge. On propose notamment des clusters PostreSQL et du PITR. Pour des questions de résilience, la base de données sera donc PostgreSQL. Encore une fois, l’utilisation d’un framework, en l'occurrence Laravel, permet de faire ce changement de moteur de base de données très facilement.
Le schéma d'architecture cible pour l'application est donc celui représenté ci-après. Heureusement, les développeurs n'ont pas besoin de connaitre tous ces détails. La plateforme Scalingo s'occupe de tout et permet aux développeurs de se concentrer sur leur vraie valeur ajoutée : le code qu'ils produisent.

De la même façon, le service d’envoi de courriels transactionnels utilisé précédemment était SendGrid. Comme il est d’usage dans la communauté Beta Gouv, et sans être des ayatollahs, s’il existe un service français ou européen équivalent il serait préférable de l’utiliser. En premier lieu la surface fonctionnelle doit au moins être aussi complète, ensuite le prix ne doit pas être trop différent. On a déjà eu de bonnes expériences avec le français Sendinblue c’est donc le service que nous allons mettre en place. De plus, étant donné le contexte exceptionnel, pouvoir communiquer en français avec un acteur français pourrait nous faciliter la vie par la suite, ce qui se vérifiera d’ailleurs.
En parallèle a lieu la première réunion sur la scalabilité : malheureusement, l’application n’envoie pas d’en-têtes de cache et d’ailleurs les assets ne sont pas compilées en incluant leur version (mécanisme qui permet de se passer de l’invalidation du cache). C’est le genre de détail d'une extrême importance lorsqu'on s'attend à un nombre très important de visiteurs uniques. Chaque requête économisée par le système de cache ou le CDN est une requête en moins à traiter par le serveur applicatif qui peut donc se concentrer sur les traitements plus lourds. Heureusement notre cher Fabien nous propose l’astuce suivante : il suffit d’intercaler un reverse proxy qui ajoute des en-têtes de cache entre les internautes et l’application Laravel elle-même ! On a justement une manière très simple de déployer et configurer des Nginx sur Scalingo. Ajouter cette pièce dans l’architecture permet d’autres possibilités intéressantes et notamment de définir du rate limiting.
On arrive donc au schéma de flux suivant :

Deux autres bonnes nouvelles viendront conclure cette journée. OCTO Technology nous confirme que l’intervention de Fabien se fera pro bono. Et Outscale, le fournisseur de Cloud IaaS sur lequel Scalingo s'appuie, nous offre les instances virtuelles sur lesquelles va s'appuyer la plateforme Scalingo pour héberger jeveuxaider.gouv.fr dans le cadre de l’effort de solidarité que nous portons.
Au sujet du Capacity Planning et des tests de montée en charge
Le Capacity Planning ou Gestion de la Capacité en français c’est garantir que l'infrastructure informatique est fournie au bon moment, au bon prix et en quantité adéquate pour tenir la qualité de service en alignement avec les besoins métiers.
Autrement dit, on aimerait bien savoir combien il faudra de conteneurs, avec quelle quantité de mémoire, quelle taille de base de données il faut choisir (quel “plan” en langage Scalingo) pour tenir l’objectif de 600 transactions / secondes. Il faut appliquer le même raisonnement à toutes les “pièces mobiles” de la plateforme : Algolia pour la recherche et Sendinblue pour l’envoi de courriels. Des contacts ont été pris immédiatement avec Algolia pour s’assurer que leur service répondra correctement à la sollicitation attendue. En ce qui concerne Sendinblue, le service sera mis en place immédiatement avec leur configuration par défaut : l’adresse de courriel émettrice est validée en quelques minutes. En effet, comme la plupart des services de type SMTP as a Service, Sendinblue veut s’assurer que l’application qui envoie les courriels n’est pas un spammer. Pour cela elle doit “vérifier” l’expéditeur. La façon la plus simple d’effectuer cette vérification est d’envoyer un lien à l’adresse de courriel et il suffit de cliquer sur ce lien pour vérifier cette adresse. Mais ceci ne suffit pas dans les cas où le flot de courriels est conséquent. Il faut passer par une validation DNS. Ceci sera fait le lendemain en même temps que le Capacity Planning du service.
J-2 : Première mise en production officielle
On sait qu’il doit y avoir une démo le vendredi matin aux officiels. On ne sait pas à quelle heure exactement. On saura après coup que la démo ne s’est pas exactement déroulée comme prévue. Dans le stress il y a eu quelques problèmes de communication au sein de l’équipe : le site était caché derrière une authentification type Basic Auth mais ce système a perturbé certains appels API. Tout est corrigé rapidement et on sait qu’une première mise en production doit intervenir dans l’après-midi afin de permettre de recruter des associations qui vont ajouter des “missions” sur la plateforme.
C’est à notre équipe qu’il revient de configurer le nom de domaine de la plateforme, c’est-à-dire covid19.reserve-civique.gouv.fr. En réalité il s’agit surtout de demander des modifications DNS précises aux services de l’État. En temps normal c’est le genre de modification qui demande plusieurs jours à être appliquée. Ici l’urgence fera loi et ça ne prendra que quelques heures. Pour plus de sécurité, nous mettons en place deux adresses IP dédiées pour la plateforme de façon à pouvoir gérer une potentielle attaque séparément du reste de la plateforme Scalingo (c’est-à-dire les applications hébergées par nos autres clients).
On arrive à établir un contact direct avec Sendinblue en fin de matinée. Notre interlocuteur nous conseille de mettre en place 2 adresses IP dédiées à l’envoi de courriels. Chaque domaine associé à ces adresses IP devra être vérifié et chaque domaine devra être déclaré correctement de façon à ce que les serveurs de courriels destinataires ne considèrent pas les courriels envoyés par la plateforme comme du spam (les fameux SPF, DKIM et DMARC). Il faut donc refaire une demande de modification DNS aux services de l’État. Ce qui prendra de nouveau quelques heures à être appliqué.
Mise en production mais diffusion restreinte
La première mise en production arrive le vendredi 20 mars à 14h, comme prévue. L’adresse du site est alors communiquée directement aux associations par des canaux privés. À ce stade elles vont pouvoir s’enregistrer sur la plateforme et proposer des missions. Comme cela est fait, la partie du site du site dédiée au recrutement de volontaires va pouvoir avoir le focus désormais.
En parallèle, on arrive à un consensus sur ce que doit être le parcours nominal qui doit au minimum fonctionner : les devs doivent limiter le parcours “Volontaire” (aboutir à une page de confirmation "votre compte sera activé dans les 24/48/xx heures", pas de possibilité de recherche de missions, désactivation des écrans de login volontaires, émission en différé des courriels de confirmation).
Premiers tests de montée en charge
Comme on connaît maintenant le parcours nominal, les scénarios de test sont construits pour les reproduire. 3 différents tests de performance pour couvrir ces scénarios ont été réalisés. Le but de ces opérations est d'être capable de définir la quantité de ressources à déployer : combien de containers, de quelle taille ainsi que le choix du plan de base de données.
Test d’accès à la page d’accueil
Le but de ce test était de vérifier que la politique de cache était bonne et que la grande majorité des requêtes utilisateurs trouvait une réponse au niveau du cache de Cloudflare et n’atteignait pas l’infrastructure hébergeant l’application en tant que tel. Seule les requêtes influant sur les données (ajout de mission, inscription volontaire, participation à une mission), devaient être envoyées à l’application Laravel.

On peut voir qu’effectivement la grande majorité du trafic est cachée par le CDN de Cloudflare, cela comprend tout le contenu static (JavaScript / CSS) ainsi que du contenu dynamique cachés pour de courts moments. Avec un tel taux de cache, ce premier test est validé.
Ces premiers tests de montée en charge nous font également douter sur un comportement de la stack applicative : l’application injecte-t-elle ou non un cookie dans chaque page vu par un internaute ? Si c’est effectivement le cas, cela rendra impossible l’utilisation d’un CDN en frontal. Il faudrait alors modifier ce comportement et stocker les sessions d’une autre manière. Sans doute dans une base de données Redis qui est tout à fait appropriée, d’autant plus que Scalingo propose des clusters Redis en self-service. Finalement, l’équipe de devs nous confirme qu’aucun cookie de session n’est transféré, donc nul besoin de mettre en place un Redis ou similaire. Bonne nouvelle pour le CDN !
Test d’inscription des volontaires
Ce test de charge est certainement celui avec le plus d’enjeux, en effet c’est celui qui va impacter le plus la base de données PostgreSQL de l’application. L’objectif est de tester jusqu’à 600 inscriptions/seconde qui est l’objectif “business”. Ce test est réalisé de manière progressive afin de pouvoir identifier les limites éventuelles et y remédier, tout d’abord 50, 100, 150, 300, 450 et enfin 600 inscriptions par seconde.
Découverte lors des tirs de charge :
Laravel a un système intégré de “rate limiting” (comprendre limite du nombre de requêtes venant d’un utilisateur unique), puisque l’application est hébergée derrières différents niveaux intermédiaires, cette dernière avait l’impression que toutes les requêtes venait de la même personne. Une modification de code a été proposée pour changer la configuration de l’application pour que le framework prenne en compte cela.
Au dessus de 75 inscriptions par seconde, les performances de l’application devenaient mauvaises, nous nous sommes rendus compte à ce moment là que des indices étaient manquants en base de données et que plus il y avait de données en base de données et plus les nouvelles inscriptions devenaient lentes. Encore une modification de code a été proposée, avec une migration de la structure de la base de données pour ajouter ce qu’il manquait. Une fois ces indices en place, le temps d’inscription est à nouveau linéaire.
À partir de 150 inscriptions par seconde, nous avons ensuite détecté un nouveau ralentissement progressif des performances. Notre équipe s’est rendu compte que la limite venait cette fois de la base de données qui n’arrivait plus à encaisser les inscriptions. Qu’à cela ne tienne, la base de données de test est migrée vers un plan plus grand (cluster de 2 nœuds avec 32 CPUs et 64Go de RAM), et à partir de là, plus de problème. La base de données accepte toutes les écritures jusqu’à 600 inscriptions/secondes avec une consommation de 16 CPUs comme montré dans la capture d’écran ci-dessous. La base de production sera taillée de la même manière.
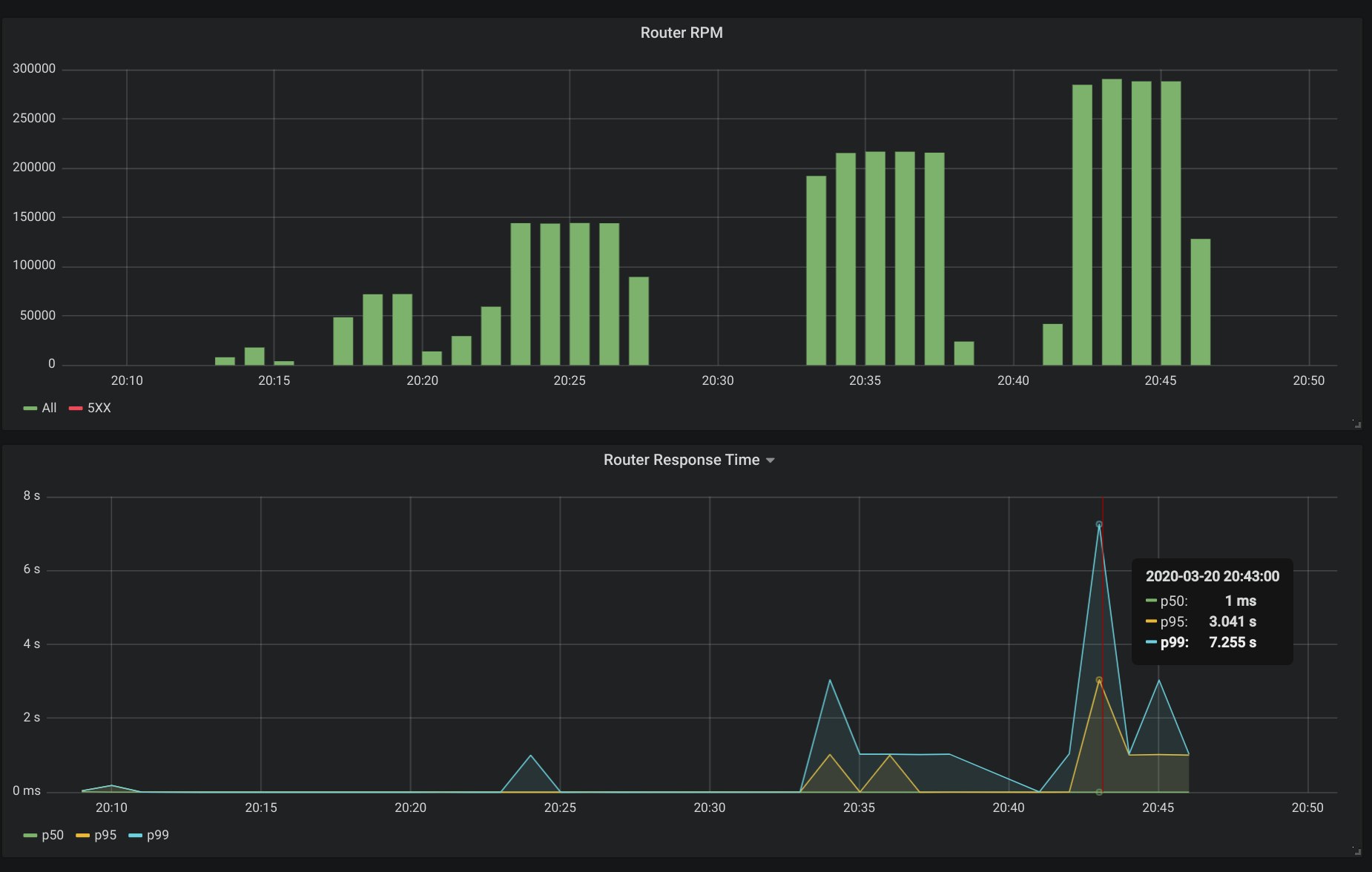
Au fur et à mesure de la montée en puissance des tests de charge, nous avons dû augmenter le nombre de containers gérant l'application PHP pour s'assurer que toutes les requêtes trouvent une réponse. Dès que, soit la mémoire dépassait la taille courante, une plus grande taille était utilisée, et si le CPU était une limite, l'application était scalée sur plus de containers.
Nous avons ainsi déterminé que pour pouvoir gérer toutes ces inscriptions de manière certaine, l'application utilisera 50 containers de taille M, associés au cluster de base de données PostgreSQL utilisant un plan Business 32CPU 64GB.
J-1 : Une fonctionnalité surprise qui change tout
Changement du nom de domaine principal
Alors que les tests de montée en charge se sont poursuivis jusque tard la nuit dernière. Il y a une nouvelle surprise sur notre chemin : l’URL du site qui sera communiqué par le gouvernement va changer et sera jeveuxaider.gouv.fr. On nous demande de faire une redirection de jeveuxaider.gouv.fr vers covid19.reserve-civique.gouv.fr. Il faut donc à nouveau faire appel aux services de l’État pour demander des modifications DNS sur ce nom de domaine. On propose que la redirection soit effectuée par Cloudflare. Cependant, contrairement à covid19.reserver-civique.gouv.fr, jeveuxaider.gouv.fr est un domaine racine et la seule méthode d’intégration de Cloudflare est de leur déléguer la gestion de la zone DNS, ce qui est exclu par les services de l’État étant donné que Cloudflare est une entreprise américaine. Il nous est demandé de rediriger la redirection d’une autre manière. La solution la plus rapide est que la redirection soit effectuée par la plateforme Scalingo sur deux adresses IP dédiées. Et comme on attend potentiellement plusieurs centaines de milliers de visiteurs, on ajoutera une nouvelle campagne de tests de montée en charge pour tester spécifiquement cette redirection. Ils seront effectués durant la journée de samedi.
Redirection de jeveuxaider.gouv.fr vers covid19.reserve-civique.gouv.fr
Comme précisé précédemment, le nom de domaine qui sera annoncé dans les médias est jeveuxaider.gouv.fr, et impossible d’utiliser Cloudflare pour rediriger le trafic. Il fallait donc vérifier que l’infrastructure tienne la charge pour accepter l’ensemble des connexions des français qui vont se rendre sur la page web. Ici nous savions que la limite ne serait pas la performance CPU/Mémoire/Base de données de l’application, mais la gestion des connexions à l’entrée de l’infrastructure.
Notre objectif pour ce test était de valider que 10 millions de français puissent se rendre sur le site dans un interval de 30 minutes, ce qui signifie : environ 8000 requêtes par seconde. À force de tirs de charges progressifs, nous avons constaté quelques ralentissement à partir de 4000 requêtes par seconde :
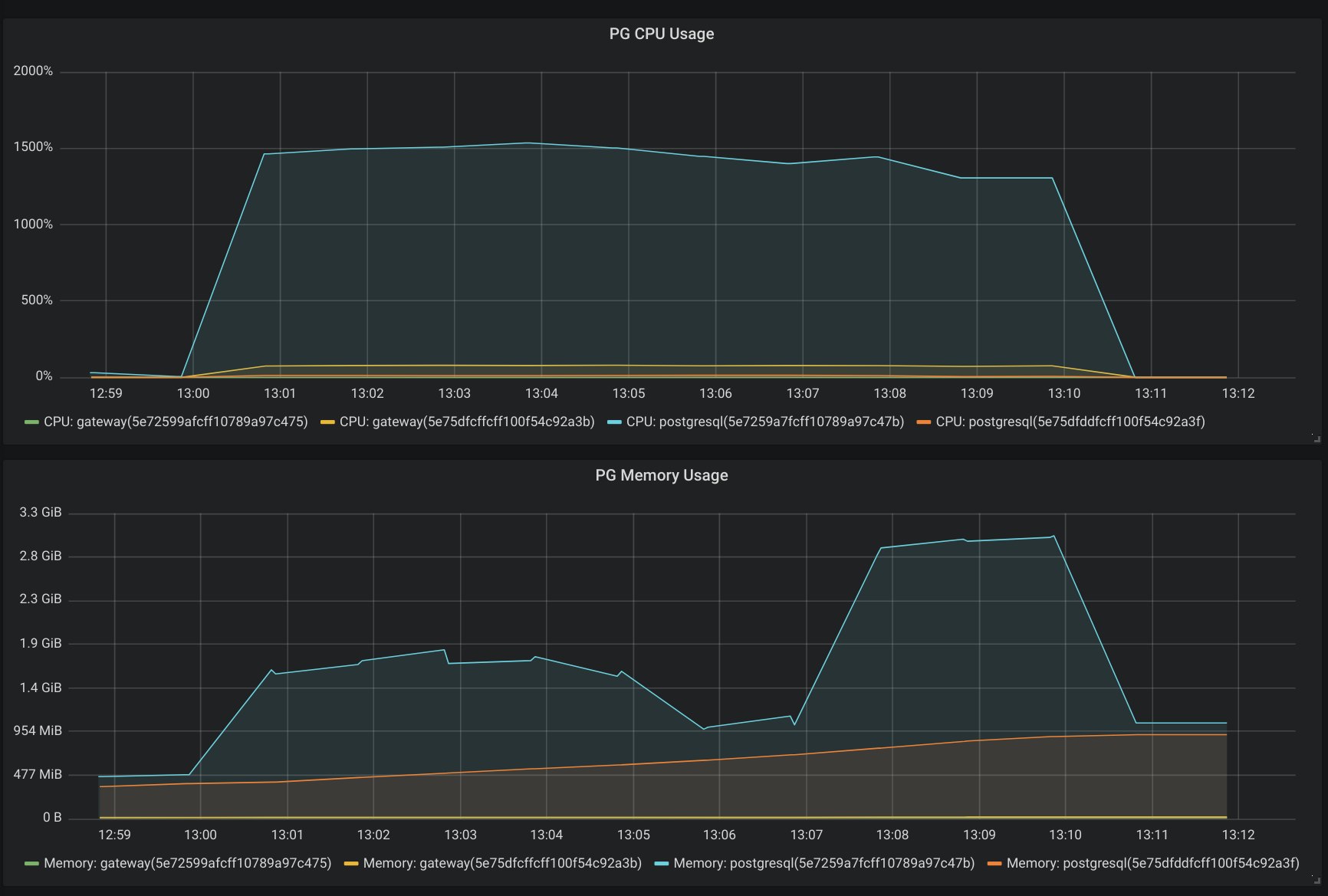
Suite à l’identification du goulot, nous avons utilisé nos outils de provisioning d’infrastructure pour augmenter la quantité de serveurs gérant le “routing” des requêtes, et le test est passé sans problème.
Mode “dégradé” de l’application
Un mode dégradé de la plateforme est développé par l’équipe de devs. Il est activable à l’aide d’une variable d’environnement. L’équipe Scalingo qui est responsable du Maintien en Condition Opérationnelle (MCO) de la plateforme a donc à sa disposition un interrupteur permettant de réduire certaines fonctionnalités pour limiter l’impact de la charge. Il s’agit de préserver les fonctions de base de la plateforme (inscription de volontaire) au détriment la surface fonctionnelle. Fort heureusement on découvrira plus tard qu’on n’aura jamais besoin d’activer ce mode dégradé.
J-0 : Annonce officielle
On est dimanche matin. L’annonce doit être effectuée le soir-même. L’équipe est confiante : les tests de montée en charge se sont bien déroulés, les ressources informatiques ont été modulées pour pouvoir accueillir un pic de trafic générant 600 transactions par seconde. L’équipe de devs produit encore quelques commits pour peaufiner l’interface et le mode dégradé. Ils seront déployés automatiquement par l’intégration GitHub.
Aux dernières nouvelles l’annonce ne devrait plus être faite par le Président de la République mais pas Gabriel Attal, secrétaire d’État. De ce fait le chef de projet s’attend à un pic moins important. La pression redescend d’un cran dans l’équipe tech. Néanmoins la vigilance reste de mise : cela reste un passage TV qui aura lieu lors d'un moment de grande écoute.
Dimanche 22 mars vers 20h30, Gabriel Attal est l’invité du journal de France 2. L’équipe tech est aux abois : on est tous connectés en même temps à la TV, pour suivre le discours, et sur Discord pour échanger en temps réel entre les membres de l’équipe. On entend des “attention il vient de parler de la plateforme”, “le pic commence !” et d’autres “la base de données consomme maintenant 2 CPUs et ça monte !”.
Finalement tout s’est déroulé conformément au plan. La plateforme a été disponible tout le temps, avec de très bons temps de réponse, sans diminuer ses fonctionnalités.
J+x
Le lendemain de l’annonce officielle lors du passage au JT de France 2 la couverture presse est abondante. Le nombre de RPM (Requêtes Par Minute) augmente d’heure en heure. D’autres passages TV surviendront à plusieurs reprises les jours suivants.
Le Président de la République reparlera lui-même de la plateforme jeveuxaider.gouv.fr lors de son discours du 25 mars devant l’hôpital militaire de Mulhouse.
Chaque passage génère un pic de trafic, brutal et bref. Chaque pic est complètement absorbé par la plateforme. L’équipe tech est très contente de constater que les données de trafic et les données de charge durant ces pics de trafic correspondent complètement à celles observées durant les simulations et tests de montée en charge !
Conclusion et apprentissages
Avec l’allocution du Président de la République on a en quelque sorte “vaincu le boss de fin de niveau”. Le plus haut pic de charge a été atteint après ce passage TV. Il est resté en-dessous du maximum testé durant les campagnes de “tir” et la plateforme s’est comportée tout à fait correctement, avec des temps de réponse excellents.
Dans un projet commando, les règles habituelles ne s’appliquent plus. Par exemple, le temps de la pédagogie est considérablement réduit. Il faut parfois trancher vite et bien. Choisir dès le départ qui fait quoi, c’est-à-dire savoir quelle est la responsabilité de chacun, est plus important. Le problème est bien entendu de savoir qui doit décider de ces rôles et responsabilités. Dans le cas d’équipes hybrides multi-disciplinaires dont les membres proviennent de plusieurs entités, c’est évidemment très difficile de savoir qui a le droit de prendre telle ou telle décision. Il faut alors faire beaucoup plus d’efforts dans la communication et dans ses gestes de bonne volonté.
Quand on s’attend à avoir un trafic qui sort de l’ordinaire sur son application web, il est toujours intéressant que les personnes en charge de la communication et qui, à priori, maîtrisent la chronologie d’apparition dans les médias, se synchronisent avec l’équipe tech de façon à ce que celle-ci soit sur le pont lors des fortes affluences et soit à même d’agir sur certains paramètres techniques afin de garantir la stabilité et la disponibilité de l’application web. Dans le cas de la plateforme jeveuxaider.gouv.fr cela n’a pas toujours été le cas. Et pour cause, l’agenda média de nos gouvernants en période de crise change d’heure en heure ! Fort heureusement, les tests de montée en charge ont été faits correctement et nous ont couvert.
De la même façon, et cela paraît évident de le dire après coup, lorsqu’on fait une démo lors d’un projet commando, c’est-à-dire dans des conditions où l’application dont on veut faire la démo change d’heure en heure. Il faut imposer un “freeze” sur les changements en production, le temps de tester le parcours dont on veut faire la démo et de réaliser effectivement la démo.
Il va sans dire que les membres de l’équipe étaient en communication constante via Slack, Discord ou appels téléphoniques. Discord est particulièrement intéressant pour suivre une “situation” à plusieurs en même temps notamment avec la fonction de “stream”. Cependant, la facilité de l’outil Discord a aussi comme inconvénient de favoriser l’oral par rapport à l’écrit. Or, certaines informations doivent être consignées à l’écrit. Il faut donc ne pas oublier d’écrire ce qui doit l’être une fois la période d’urgence passée.
Lors de nos tests de montée en charge, nous avons vu que le facteur limitant de la bases de données a été le CPU plutôt que la mémoire. Nos plans de bases de données sont aujourd’hui conçu de manière équilibrée entre le CPU et la mémoire. Un peu comme les VMs, nous allons ajouter dans les mois qui viennent des plans de bases de données boostées en CPU.
Si dans l’intervalle vous avez ce genre de besoins, n’hésitez pas à nous contacter. Notre équipe tech sera ravie de vous proposer un plan de base de données sur mesure qui correspond exactement à vos besoins ou spécifications.

Yann Klis
Yann KLIS a fondé Scalingo en 2015 avec son associé Léo Unbekandt avec la vision de proposer une plateforme cloud d'hébergement web, véritable alternative européenne et souveraine aux géants américains. Aujourd'hui Scalingo héberge plusieurs milliers d'applications web déployées par des clients du monde entier ! L'objectif de Scalingo est de devenir la plateforme cloud de référence pour les développeurs web en Europe. Auparavant, il a fondé Novelys, un studio de développement spécialisé dans la technologie Ruby on Rails.
Restez informé
Recevez des articles et des mises à jour de la plateforme dans votre boîte de réception.
Prêt à déployer en toute confiance ?
Découvrez des déploiements sans temps d'arrêt, une mise à l'échelle automatique intelligente et une infrastructure entièrement gérée. Commencez à déployer vos applications sur Scalingo dès aujourd'hui.
Aucune carte de crédit requise • Déployez en quelques minutes • Annulez à tout moment





