4 min de lecture
Ajoutez l’IA à vos projets PostgreSQL avec pgvector sur Scalingo
pgvector introduit un nouveau type de colonne dans PostgreSQL pour stocker des tableaux de nombres à virgule flottante, appelés vecteurs — chaque valeur correspondant à une dimension d’un embedding.

Sans vouloir céder à la nostalgie, il faut reconnaître que la recherche a beaucoup évolué depuis l’époque où l’on comptait sur une requête du type LIKE'%keyword%' pour trouver ce qu’on cherchait.
Aujourd’hui, on attend des applications qu’elles comprennent nos intentions, pas seulement nos mots. Qu’il s’agisse de recommandations, de réponses ou de simples recherches, elles doivent être capables de saisir le sens derrière nos requêtes.
C’est précisément ce que pgvector apporte à PostgreSQL. L’extension permet de stocker et de comparer des vecteurs, représentations numériques (embeddings) générées par des modèles d’apprentissage automatique à partir de textes, d’images ou de tout autre type de données.
Les vecteurs capturent les relations de sens apprises par le modèle : deux éléments proches par leur signification auront des vecteurs voisins dans l’espace. Résultat : la base de données peut retrouver des contenus similaires en signification, et non plus seulement identiques sur le plan textuel.
Sur Scalingo, pgvector est déjà disponible sur nos bases managées PostgreSQL. Aucune installation, aucune configuration nécessaire : il suffit d’activer l’extension.
En quelques minutes, vous pourrez mettre en place de nouvelles fonctionnalités comme la recherche sémantique, les recommandations intelligentes ou la classification automatique de contenu. Le tout, sans déplacer vos données, directement dans vos bases existantes.
Alors, concrètement, que fait pgvector ?
Si l'on devait résumer, pgvector ajoute un nouveau type de colonne à votre base PostgreSQL : une colonne capable de stocker un vecteur, c’est-à-dire un tableau de nombres à virgule flottante. Chaque nombre représente une dimension d’un embedding.
“ Le vecteur est le type de donnée que pgvector ajoute à PostgreSQL. Concrètement, c’est une colonne de nombres. L’embedding, lui, correspond à ce que ces nombres représentent : une traduction numérique d’un texte, d’une image ou de tout autre contenu. ”
Le nombre de dimensions dépend du modèle que vous utilisez : par exemple, 384 for all-MiniLM-L6-v2 par Hugging Face (un petit favori chez nous 🤗), ou 1536 pour les text embeddings d'OpenAI.
Et si jamais vous avez besoin de plus de place, pas d’inquiétude : pgvector gère jusqu’à 16 000 dimensions, de quoi couvrir les modèles les plus ambitieux du moment.
Plus de dimensions ne signifient cependant pas forcément « de meilleurs » résultats. Elles reflètent simplement le niveau de détail avec lequel le modèle encode les relations entre mots ou concepts. Les petits embeddings sont typiquement plus rapides et légers ; les plus grands, eux, capturent davantage de nuances lorsque la précision s’impose.

pgvector est implémenté en C et s’exécute directement au sein du moteur PostgreSQL. Comme tous les calculs se font à l’intérieur du processus de la base de données, les opérations telles que la similarité cosinus ou la distance euclidienne restent rapides et efficaces. Même sur de grands volumes de données.
--> La similarité cosinus mesure l’angle entre deux vecteurs. Elle est idéale pour comparer le sens de deux éléments. La distance euclidienne, elle, mesure la distance “en ligne droite” entre ces vecteurs, et est plus adaptée aux données spatiales ou numériques. Toutes deux permettent à la base de données de déterminer quels éléments se ressemblent le plus, simplement selon des points de vue différents.
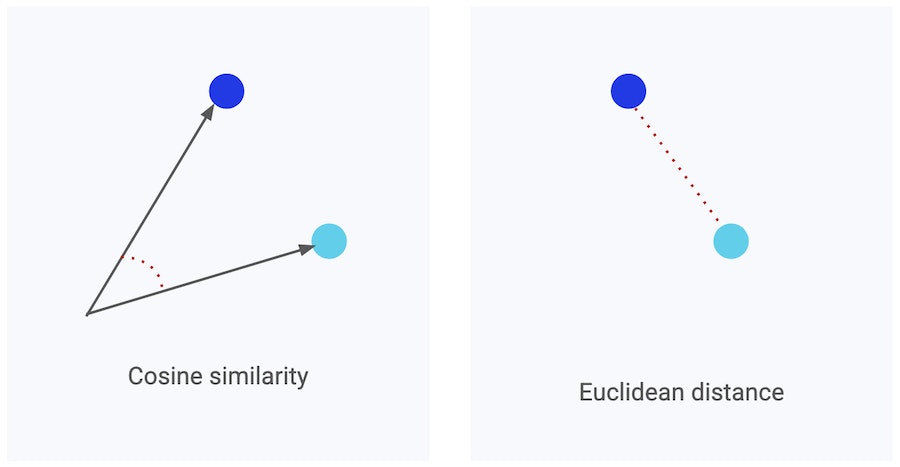
Vous pouvez donc choisir la mesure de similarité la plus adaptée à votre cas d’usage : la similarité cosinus est souvent privilégiée pour les embeddings de texte, tandis que la distance euclidienne fonctionne mieux avec des images ou des caractéristiques numériques.
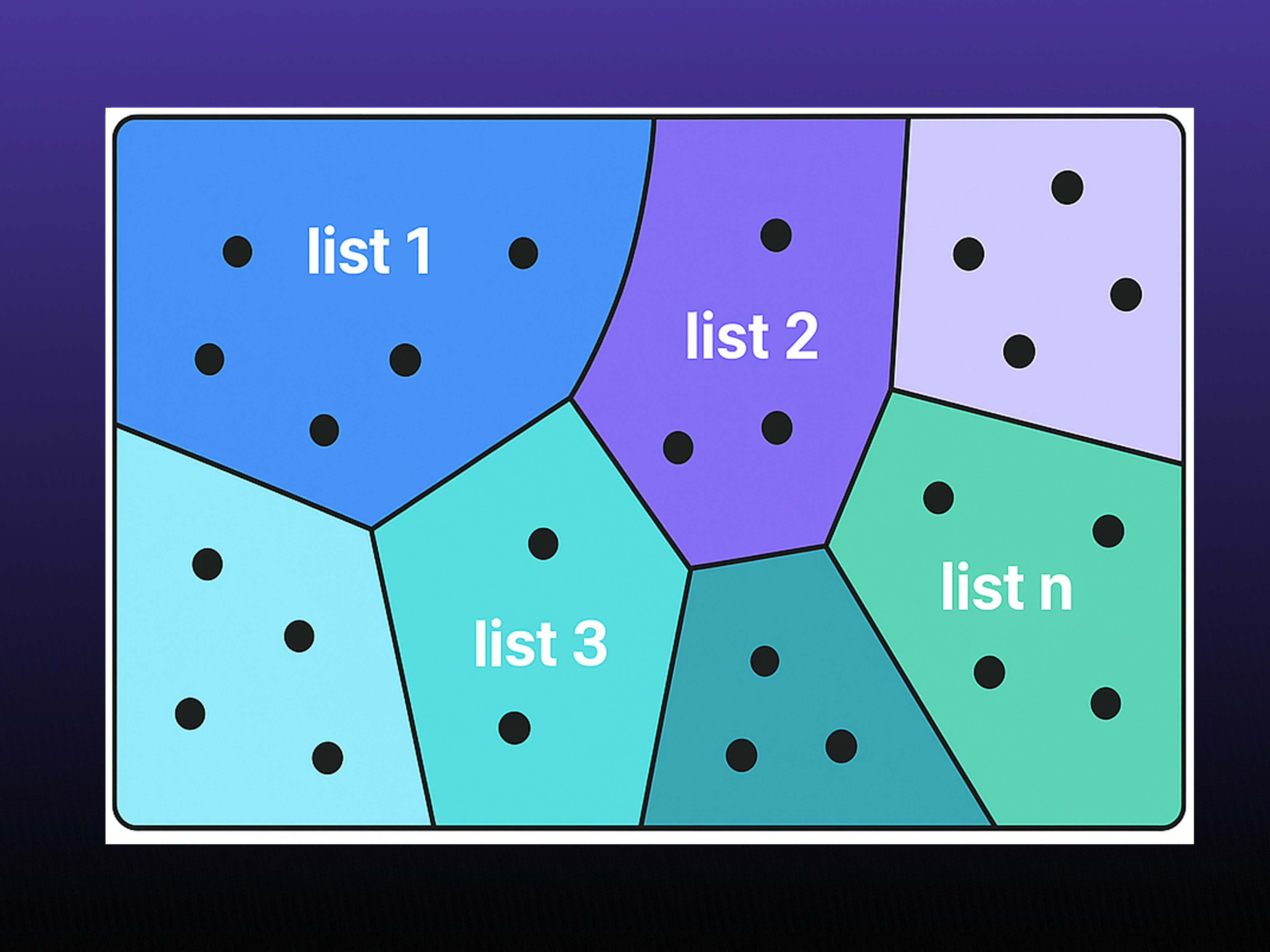
pgvector prend également en charge l’indexation via IVFFlat, une méthode qui regroupe les vecteurs en clusters afin que les requêtes ne parcourent que les plus pertinents. Il est possible d’ajuster le nombre de clusters (appelés "lists") pour trouver le bon équilibre entre vitesse et précision : plus il y a de "lists", plus les recherches sont rapides, mais au prix d’une consommation mémoire légèrement plus élevée.
Quand pgvector a du sens… et quand il n’en a pas
Pour beaucoup d’équipes, et notamment celles qui veulent ajouter des fonctionnalités alimentées par l’IA au sein de leurs systèmes existants, pgvector est un excellent choix : assez rapide pour la production, assez simple pour être adopté facilement, et assez souple pour évoluer avec leurs besoins.
Comme pgvector est totalement "agnostique du modèle", vous pouvez enrichir votre base PostgreSQL avec des embeddings issus de Hugging Face, OpenAI, ou même de vos propres modèles, et commencer à expérimenter sans attendre. Pas d’infrastructure supplémentaire, ni de nouveaux services à maintenir.
Autre avantage : puisque pgvector fonctionne au cœur même de PostgreSQL, il est parfait pour prototyper rapidement. Vous pouvez passer d’une idée à une fonctionnalité prête pour la production sans changer d’environnement ni complexifier votre architecture.
En revanche, si votre activité repose surtout sur des requêtes structurées ou des recherches exactes, pgvector ne vous apportera pas grand-chose. Les index PostgreSQL traditionnels (comme B-tree ou GIN) font déjà très bien le travail.
“ Les index B-tree sont parfaits pour les données bien structurées, comme les identifiants utilisateurs, les dates ou les prix. Les index GIN, eux, excellent dès qu’il s’agit de tableaux, de JSON ou de recherche plein texte. ”
Enfin, si vous jouez dans la cour des géants (on parle ici de milliards de vecteurs ou de recherches à très faible latence), PostgreSQL associé à pgvector finira par montrer ses limites. Dans ce cas, il peut être judicieux de se tourner vers une base de données vectorielle spécialisée, comme la solution européenne Weaviate🇳🇱.
Combiner pgvector et les LLMs
Si vous avez expérimenté avec les grands modèles de langage, ou LLMs, ces derniers temps (et honnêtement, qui ne l’a pas fait ? 😛), vous avez sans doute croisé le concept de RAG, ou Retrieval-Augmented Generation.
L’idée est simple : enrichir le modèle avec vos propres données, pour que ses réponses soient plus précises, actuelles et pertinentes, plutôt que de se limiter à ce qu’il a appris lors de son entraînement.
C’est là que pgvector entre en scène.
Il apporte à PostgreSQL la brique manquante pour ce type d’architecture : la recherche de similarité directement dans la base de données.
Des outils comme LangChain ou LlamaIndex s’occupent de la partie applicative (génération des embeddings, appels aux modèles, combinaison des résultats) tandis que pgvector gère la recherche et la récupération des données au sein même de PostgreSQL.
Résultat : vous pouvez construire un pipeline RAG complet pour de nombreux cas d’usage sans déployer de service vectoriel séparé, ni déplacer vos données en dehors de votre base existante.
—> Nous publierons très prochainement des tutoriels et des démonstrations pratiques pour vous guider dans l’intégration des LLM et de pgvector dans des cas d’usage réels.
Ce que nos utilisateurs font avec pgvector sur Scalingo
Nous sommes ravis de voir de plus en plus d’équipes expérimenter avec pgvector sur Scalingo : des petites startups qui testent des fonctionnalités d’IA jusqu’aux entreprises plus établies qui ajoutent des fonctions de recherche intelligente ou de recommandation à leurs produits existants.
Si vous cherchez de l’inspiration, voici quelques exemples de la manière dont les équipes l’utilisent déjà :
Recherche intelligente : ajoutez une recherche sémantique à vos outils de support ou à vos bases de connaissances internes, pour retrouver facilement la bonne information même lorsque les mots ne correspondent pas exactement.
Recommandations personnalisées : exploitez les embeddings pour identifier et suggérer des éléments similaires, qu’il s’agisse de contenus, d’annonces ou de produits, directement depuis votre base PostgreSQL.
Assistants internes : stockez les embeddings de vos documents afin que vos chatbots internes puissent répondre directement aux questions à partir des données de votre entreprise. → C’est d’ailleurs l’une des configurations les plus populaires parmi les utilisateurs de Scalingo.
Taggage automatique : utilisez pgvector pour regrouper et taguer vos contenus automatiquement, et ainsi gagner du temps (et préserver votre santé mentale) à mesure que vos jeux de données s’agrandissent.
“ Vous utilisez pgvector sur Scalingo ? On serait ravis d’en savoir plus sur votre projet ! ”
pgvector sur Scalingo: à vous de jouer !
Comme on l’a vu, pgvector est déjà disponible sur les bases PostgreSQL managées de Scalingo. Aucune installation, ni configuration supplémentaire n'est nécessaire : il suffit d’activer l’extension, de lancer vos tests et de voir ce que vos données ont à raconter.
Pour activer l’extension dans votre base PostgreSQL, exécutez simplement la commande SQL suivante :
Pour en savoir plus, consultez notre documentation complète sur l'activation des extensions sur Scalingo
Et comme tout tourne sur Scalingo, vous profitez automatiquement de tous les avantages de la plateforme : sauvegardes automatiques, supervision intégrée, scaling en un clic et hébergement des données en Europe. Bref, tout ce qu’il faut pour construire, sans vous soucier de la maintenance.
Bien sûr, notre équipe support est toujours là pour vous accompagner à chaque étape 💪

Jennifer Taylor
Chez Scalingo, Jennifer pilote les initiatives de croissance et de marketing, et contribue à façonner la voix de l’entreprise dans l’écosystème en pleine évolution du PaaS et du cloud. Elle aime particulièrement transformer des concepts cloud complexes en idées simples et accessibles.
Restez informé
Recevez des articles et des mises à jour de la plateforme dans votre boîte de réception.
Prêt à déployer en toute confiance ?
Découvrez des déploiements sans temps d'arrêt, une mise à l'échelle automatique intelligente et une infrastructure entièrement gérée. Commencez à déployer vos applications sur Scalingo dès aujourd'hui.
Aucune carte de crédit requise • Déployez en quelques minutes • Annulez à tout moment




