4 min read
pgvector on Scalingo: Add AI and Semantic Search to PostgreSQL
In short, pgvector adds a new column type to your PostgreSQL database that stores an array of floating-point numbers (called vectors). One for each dimension in an embedding.

We don’t mean to sound nostalgic… but search has come a long way since the days of crossing our fingers and hoping a LIKE '%keyword%' query would return something useful.
As users, we don’t want to type exact words anymore. We expect systems to simply understand what we mean. Whether it’s suggesting similar products, answering questions in plain language or finding related articles, apps now need to automatically 🪄 understand the context and intent around our requests.
That’s what pgvector brings to PostgreSQL. Simply put, it lets you store and compare embeddings, which are numerical representations of text, images, or other data that capture what they represent. And with embeddings your database can find things that are similar in meaning, not just identical in text.
On Scalingo, pgvector is already available on our managed PostgreSQL databases. There’s nothing extra to install or set up. Just enable the extension and start playing around.
In no time, you’ll be able to set up things like semantic search, smart recommendations, and automatic content classification, all without moving your data out of the database you already use and trust.
So, what does pgvector actually do?
In short, pgvector adds a new column type to your PostgreSQL database that stores an array of floating-point numbers (called vectors). One for each dimension in an embedding.
“ While Vector is the actual data type that pgvector adds and is literally a column of numbers, Embeddings are what those numbers mean. A numerical representation of your text, images, etc. ”
The number of dimensions in an embedding depends on the model you use: for example, 384 for Hugging Face’s all-MiniLM-L6-v2 (our personal favorite 🤗), or 1536 for OpenAI’s text embeddings.
And if you ever need more room, pgvector supports vectors with up to 16,000 dimensions, which is plenty for even the largest modern models.
More dimensions don’t always mean “better” results though: they reflect how much detail the model encodes about relationships between words or concepts. Smaller embeddings are often faster and lighter, while larger ones can capture more nuance when you need it.

To handle these embeddings efficiently, pgvector, written in C, integrates directly into PostgreSQL’s engine. Because the math, such as cosine similarity and Euclidean distance, happens inside the database process, similarity searches stay fast and scalable, even on very large datasets.
--> While cosine similarity measures the angle between two vectors (great for comparing meaning), while Euclidean distance measures the straight-line distance between them (useful for spatial or numerical data). Both help your database understand which items are most alike, just from slightly different perspectives.
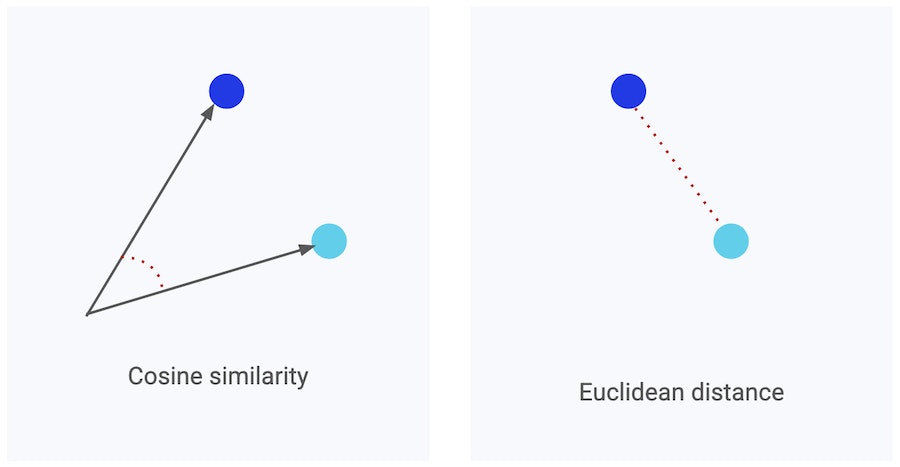
You can choose the metric that best fits your use case: cosine similarity being often preferred for text embeddings, while Euclidean distance tends to work better for images or numerical features.
pgvector also supports indexing through IVFFlat, which groups vectors into clusters so queries only search within the most relevant ones. You can tune the number of clusters (called lists) to balance speed and accuracy. More lists generally mean faster results, at the cost of slightly higher memory use.
When pgvector makes sense (and when it doesn’t)
For most teams, especially those wanting to explore AI-powered features inside their established systems, pgvector is the perfect choice: fast enough for production, simple enough for teams to quickly adopt, and flexible enough to grow with you.
As pgvector is completely model-agnostic, you can enrich your PostgreSQL database with embeddings from Hugging Face, OpenAI, or your own model and start experimenting right away. No new infrastructure is required, and no extra services need to be maintained.
And because pgvector operates inside PostgreSQL, it’s also ideal for prototyping. You can move from an early proof-of-concept to a production-ready feature using the same database.
If, however, your workload is mostly about structured queries or exact lookups, pgvector won’t add much. Standard PostgreSQL indexing (like B-tree or GIN) already handles this perfectly.
“ 💡 While B-tree indexes are great for things like user IDs, dates, or prices, GIN indexes work best for arrays, JSON, or full-text search. ”
If you’re operating at massive scale, think billions of vectors or ultra-low-latency search, PostgreSQL + pgvector will also eventually show its limits. In that case, you may want to turn to a specialized vector database such as European Weaviate 🇳🇱, designed specifically for distributed, in-memory similarity search and millisecond response times.
Combining pgvector with LLMs
If you’ve been playing with large language models (LLMs) lately (who hasn’t? 😛), you’ve probably come across Retrieval-Augmented Generation (RAG): the idea of giving a model extra context from your own data so its answers stay accurate and relevant, rather than relying entirely on what it learned during training.
pgvector gives PostgreSQL the missing piece for this kind of setup, adding similarity search inside your database.
While tools like LangChain or LlamaIndex manage the application logic (generating embeddings, orchestrating model calls, combining results…) pgvector handles the retrieval side within PostgreSQL. That means you can build a full RAG pipeline for many use-cases without introducing a separate vector-only service or moving your data out of your database.
—> Stay tuned! We’ve got some easy-to-follow tutorials and demos coming up soon to show you how to bring LLMs and pgvector together in real projects
What teams are building with pgvector on Scalingo
We’re excited to see more and more teams experimenting with pgvector on Scalingo: from small startups testing AI features to larger companies adding smarter search or recommendations to existing products.
If you’re looking for inspiration, here are a few ways teams are putting it to work:
Smarter search: add semantic search to your support tools and internal knowledge bases, making it easy to find the right information even when the words don’t match exactly.
Personalized recommendations : use embeddings to find and suggest similar items, whether that’s content, listings, or products, directly from your PostgreSQL database.
Internal assistants : store embeddings of your docs so internal chatbots can answer questions directly from your company data. → This is becoming one of the most popular setups among Scalingo users.
Automatic tagging : use pgvector to group and tag your content automatically, saving time (and sanity) as your datasets grow.
“ If you’re already experimenting with pgvector on Scalingo, we’d love to hear about your project and how you’re using it. ”
pgvector on Scalingo: ready when you are!
As we said, pgvector is already available on managed PostgreSQL databases on Scalingo. No setup & no extra configuration is required. Just enable the extension, start experimenting, and see what your data can teach you.
Simply use the following SQL statement to enable the extension in your PostgreSQL database:
Read our full documentation on enabling extensions, here
Because everything runs on Scalingo, you naturally also get the benefits that come with it: automatic backups, monitoring, scaling, and European data hosting, so you can focus on building, not maintaining.
And, as always, our support team is there to support you every step of the way!

Jennifer Taylor
At Scalingo, Jennifer leads growth and marketing initiatives, helping shape the company’s voice in the fast-evolving PaaS and cloud ecosystem. She loves translating complex cloud concepts into clear, engaging insights.
Stay Updated
Get articles and platform updates in your inbox.
Ready to Deploy with Confidence?
Experience zero-downtime deployments, intelligent auto-scaling, and fully managed infrastructure. Start deploying your applications on Scalingo today.
No credit card required • Deploy in minutes • Cancel anytime





