4 min de lecture
Créez un RAG en quelques minutes avec OpenSearch® et Scalingo
Mettre en place un système de Retrieval-Augmented Generation (RAG) nécessitait autrefois de combiner plusieurs outils complexes. Avec OpenSearch® et Scalingo, le processus est désormais beaucoup plus simple.

Auparavant, si vous souhaitiez créer un système RAG (Retrieval-augmented generation ou génération augmentée par récupération en français), il était nécessaire de combiner un certain nombre d’outils distincts. Aujourd’hui, le processus est beaucoup plus simple et se résume, par exemple, à Hugging Face, pour obtenir un modèle, et OpenSearch® pour la base de données vectorielle. Dans cet article, nous allons vous détailler le processus et vous expliquer comment créer votre propre RAG à l’aide de Scalingo et de notre offre OpenSearch®.
📼 Si vous préférez regarder plutôt que lire, voici la version vidéo de ce tutoriel :
Premiers pas et mise en place
Première étape, créer ou se connecter à votre compte Scalingo. Attention, les 30 jours d’essai gratuits proposés lors de l’inscription ne couvrent pas l’utilisation d’OpenSearch®. Si vous souhaitez suivre ce tutoriel dès maintenant, nous vous invitons donc à mettre fin à votre offre d’essai dans les paramètres. Vous pouvez également choisir de profiter de ces 30 jours offerts pour tester les autres capacités de la plateforme, puis revenir à ce tutoriel plus tard.
💡 Plus d’informations sur notre offre d’essai et ce qu’elle contient.
Une fois votre compte créé, allez sur le site d’OpenSearch® et sélectionnez l’un des modèles pré-entraînés par l’organisation. Dans notre exemple, nous avons choisi huggingface/sentence-transformers/all-MiniLM-L6-v2.
Création des applications sur Scalingo
Retournez maintenant sur le tableau de bord Scalingo. Nous allons créer une application sur la plateforme, pour mettre en place OpenSearch® Dashboard.
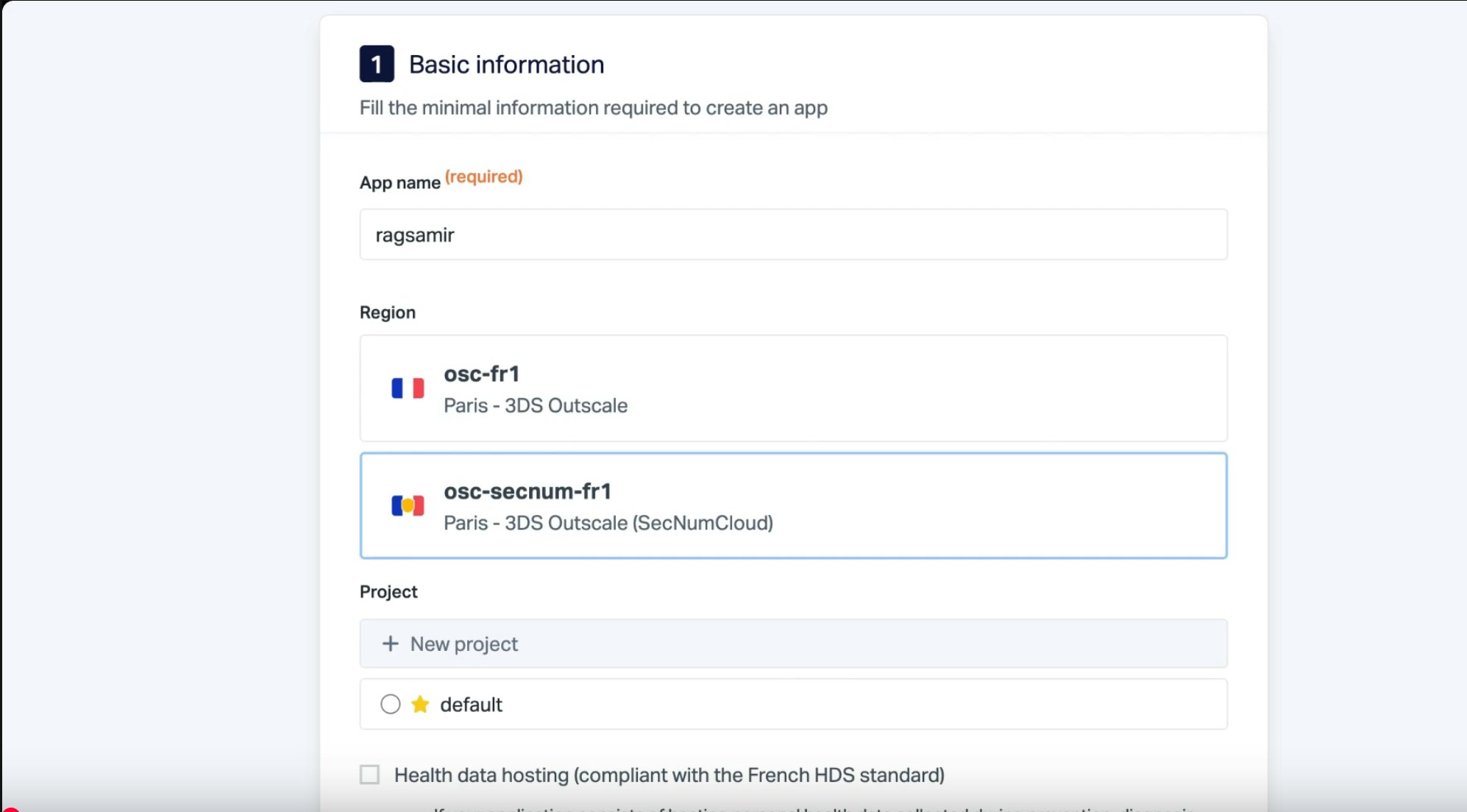
Sélectionnez l’option qui utilise Git pour le déploiement, et sélectionnez notre offre HDS ou la région qualifiée SecNumCloud, proposée par notre partenaire Outscale, si votre programme risque de contenir des données sensibles. Sinon, laissez l’option par défaut.
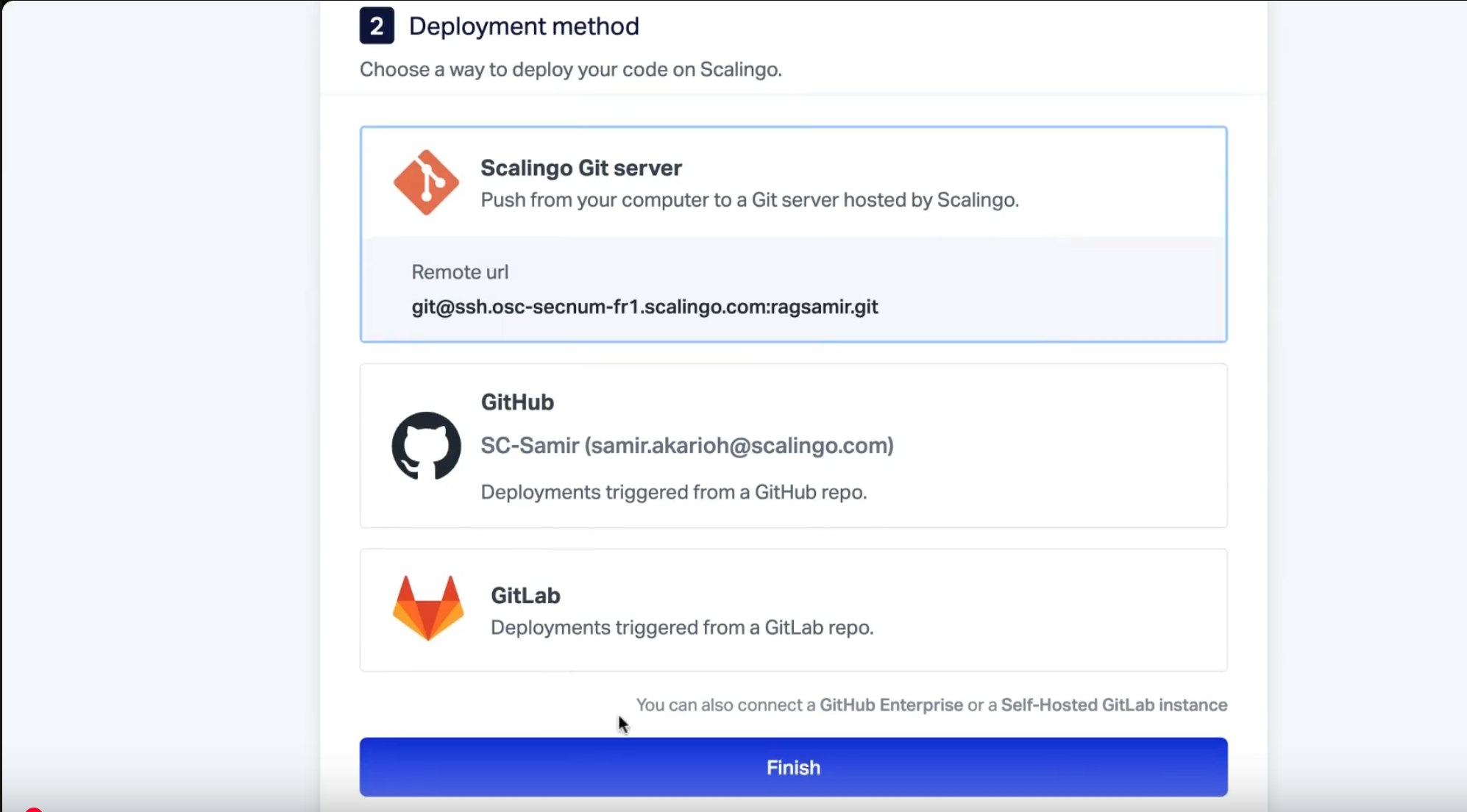
De retour dans le tableau de bord Scalingo, il est temps d'ajouter une base de données OpenSearch® à notre application. Pour ce faire, cliquez sur votre application et dans la section « addons », cliquez sur « gérer ». Ensuite, cliquez sur « ajouter un addon » et sélectionnez OpenSearch®.
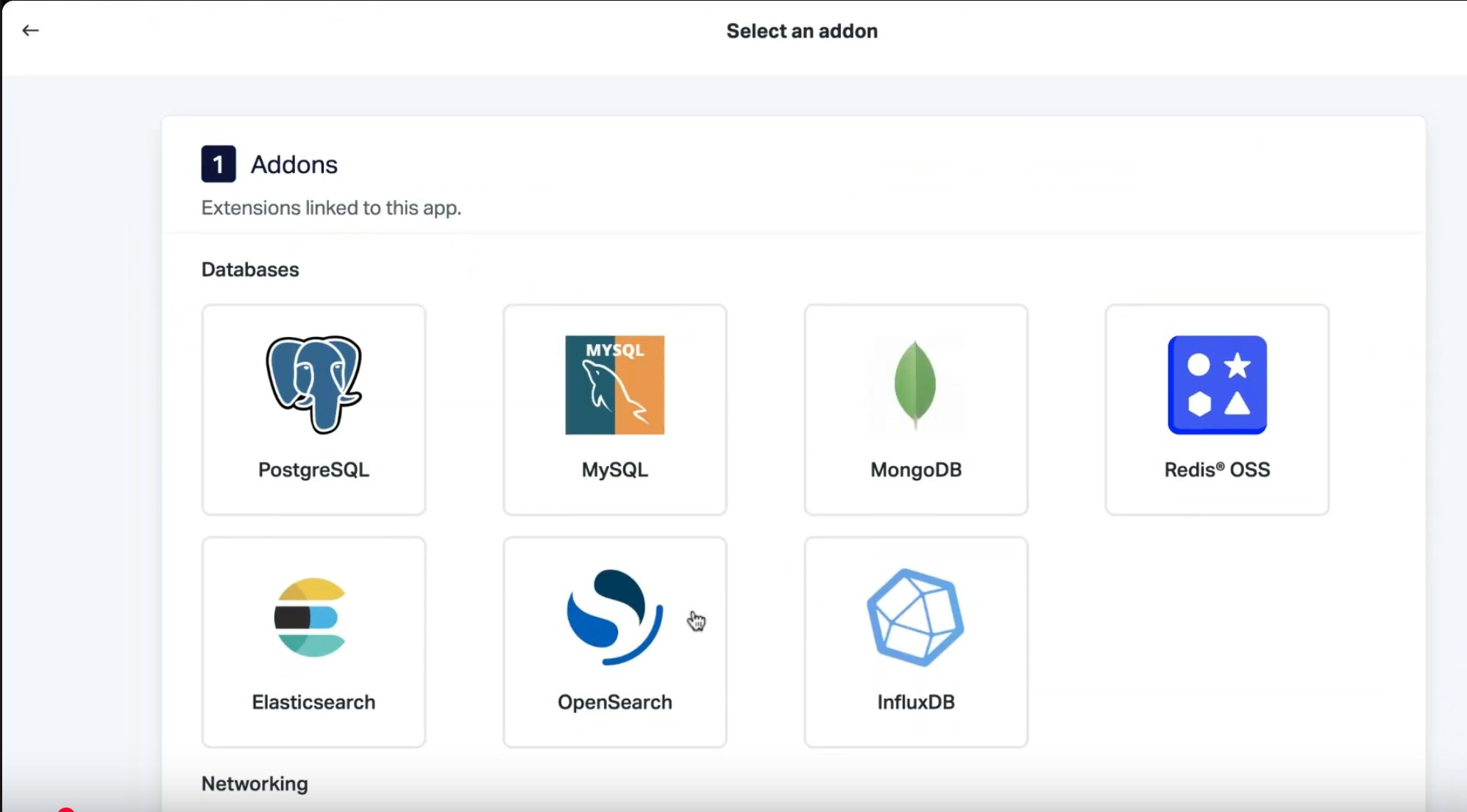
Nous proposons différents plans pour nos offres de bases de données, selon vos besoins. Cependant, pour cette application, nous vous conseillons de sélectionner un plan business, pour profiter de la haute disponibilité et des multi nodes. Validez votre choix et attendez que votre base de données soit provisionnée.
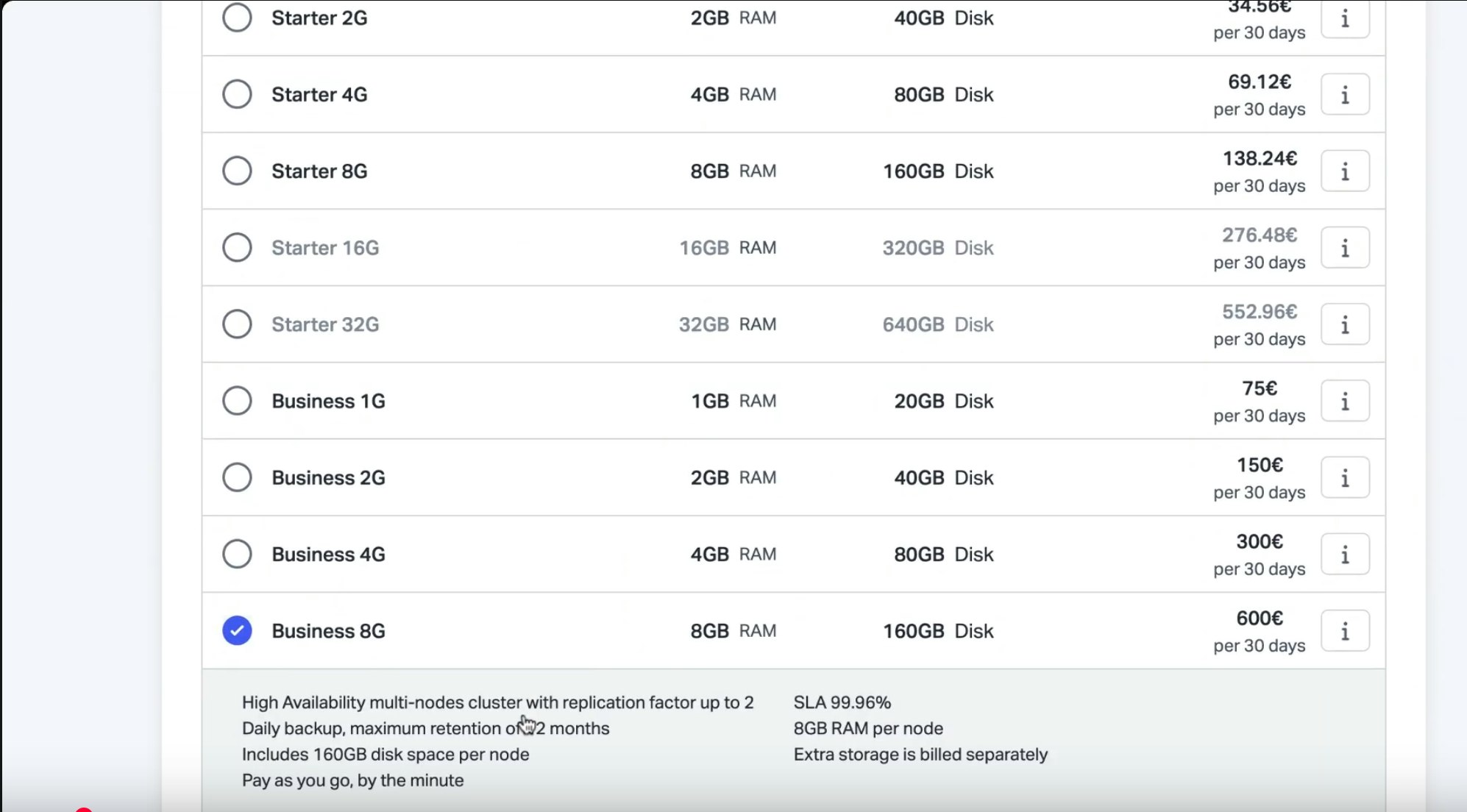
💡 Besoin de conseils pour bien choisir votre plan ? Visitez notre comparatif ou contactez nos équipes directement.
Désormais, installez le dashboard OpenSearch®. Pour ça, dans la partie variables d’environnement de votre application OpenSearch® Dashboard, entrez cette variable d’environnement :
Installer le dashboard OpenSearch® facilitera le suivi des différentes étapes et nous permettra d’accéder aux DevTools.
Dans votre éditeur de code, clonez notre répertoire pour OpenSearch® Dashboard :
Naviguez dans le dossier (cd) et ajoutez la connexion remote avec git remote add scalingo + l’URL distante de votre application OpenSearch® Dashboard sur Scalingo. Enfin, il vous suffit de push votre commit sur Scalingo.
Mise en place du modèle et des vecteurs
Maintenant, il est temps de déployer et de répertorier le modèle sur OpenSearch®. Répertorier le modèle permettra d’indiquer à OpenSearch® comment communiquer avec votre serveur de modèle personnalisé. Pour cela, votre modèle doit être au format ONNX. Vous pouvez trouver plus d’informations sur la configuration de votre modèle sur sa page sur Hugging Face.
Retournez sur Scalingo et sélectionnez l’application qui contient le dashboard OpenSearch®. Assurez-vous que la page du dashboard OpenSearch® s’ouvre correctement. Connectez-vous avec vos informations utilisateurs, que vous pouvez trouver sur votre application dans la variable d’environnement SCALINGO_OPENSEARCH_URL , et sélectionnez les DevTools.
À ce moment, il est important d’ajouter les paramètres suivants :
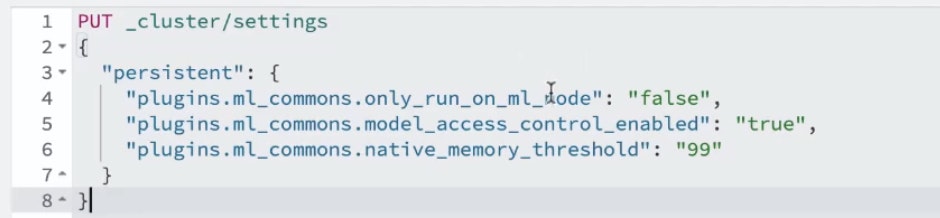
Le premier réglage permet à OpenSearch® de télécharger le modèle en ligne ;
Le second permet au modèle d'être lancé sur tous les nœuds d’OpenSearch® ;
Les deux derniers retirent les limites de mémoire et activent le contrôle d’accès.
Ces paramètres sont cruciaux pour garantir que votre modèle soit correctement chargé et optimisé sur l’ensemble de votre cluster.
C’est également ici que vous pourrez enregistrer votre groupe de modèles, en rentrant cette requête dans les DevTools. Vous pouvez choisir le nom que vous désirez pour votre groupe, et il est nécessaire de conserver l’ID obtenu après avoir envoyé votre requête.
Suivez les étapes 4 et 5 de la page pour finaliser l’enregistrement de votre modèle et son déploiement. Toutes les informations sur votre modèle choisi, comme son nom et sa version, sont disponibles sur le site d’OpenSearch®. À la fin de ces étapes, conservez l’ID de votre modèle.
Désormais, vous allez avoir besoin d’un moyen de convertir vos documents en embeddings. Pour cela, il faut créer un pipeline d’ingestion, en réalisant l’opération décrite ici. Assurez-vous de modifier le champ model_id pour y mettre l’ID obtenu à l’étape précédente.
Maintenant, il est nécessaire de créer un index vectoriel. Un index vectoriel est une structure qui vous permet de stocker et d’extraire efficacement des vecteurs. Entrez la requête indiquée sur le site d’OpenSearch® et assurez-vous de modifier le champ “default_pipeline” pour qu’il corresponde au nom que vous avez donné à votre pipeline créée lors de l’étape précédente. À noter également : assurez-vous que la dimension de votre mapping corresponde à la dimension de l’output de votre modèle.
Enfin, nous allons ajouter des documents à notre index. Pour cela, entrez les documents que vous souhaitez à l’aide de cette requête :
Réalisez l’opération autant de fois que nécessaire, en modifiant le chiffre à la fin de l’endpoint, comme visible dans cet exemple.
Vous pouvez également ajouter des données en masse, à l’aide de l’endpoint /_bulk, comme dans cet exemple. Assurez-vous de modifier l’index afin qu’il corresponde au vôtre.
Une fois cette étape passée, vous pouvez mettre en place votre pipeline de recherche et envoyer une requête pour vous assurer que tout fonctionne. La requête est disponible ici. N’oubliez pas de modifier la requête pour y ajouter votre propre ID de modèle.
Conclusion
Désormais, vous avez tout ce qu’il faut pour créer votre RAG avec OpenSearch® et Scalingo : de quoi générer vos embeddings automatiquement et un pipeline d’ingestion. Il vous suffit d’ajouter des documents au sein de votre index OpenSearch® pour pouvoir réaliser des requêtes au sein du dashboard d’OpenSearch®.
Besoin de plus de conseils pour savoir comment utiliser OpenSearch® avec Scalingo ? Contactez nos équipes, qui se feront un plaisir de vous guider.

Samir Akarioh
Samir est DevRel chez Scalingo, un rôle entre le marketing et la technique, deux sujets qui le passionnent. Son but ? Transmettre son savoir aux développeurs et utilisateurs de Scalingo.
Restez informé
Recevez des articles et des mises à jour de la plateforme dans votre boîte de réception.
Prêt à déployer en toute confiance ?
Découvrez des déploiements sans temps d'arrêt, une mise à l'échelle automatique intelligente et une infrastructure entièrement gérée. Commencez à déployer vos applications sur Scalingo dès aujourd'hui.
Aucune carte de crédit requise • Déployez en quelques minutes • Annulez à tout moment





