Docker Containers Monitoring
At its core, Scalingo is about running Docker containers. Each of these containers has to be monitored in order to get meaningful data for our users and for us as a provider. At the APIDays Berlin and APIStrat Europe 2015 event, I gave a talk about the different APIs which can be used to monitor containers on a server. It deals with Docker Stats API limits and how to access data from the Linux control groups and namespaces created by Docker and the Acadock open source project which is the result of my investigations on the subject.
Since Docker 1.5, its remote API contains one endpoint to get metrics from containers running on your hosts: GET
/containers/:id/stats. The Docker daemon answer with a stream of JSON containing, for each second, all the possible metrics for the given containers. There is one main issue with that: there is no way to parameterize the obtained data. When running numerous containers on a server and you want to monitor all of them, it will quickly result in a load issue. Monitoring 200 containers with the Docker API may take up to one full CPU core, which is really too much for a monitoring solution. There is no way to modify the one-second period between each metrics sending and it is not possible to specify which data are sent. It results in a lot of useless system calls, creating an important overhead.
That’s why it may be interested to fetch the information from the source, the Linux kernel. Docker is using two kernel mecanisms to isolate processes from each other, these features are also the one which allowed us to get information per container. First the control groups let us get metrics about the CPU, memory, and disks IO of a container. These information can be found in the directory of the different controllers: cpuacct, memory and blkio
Standard: /sys/fs/cgroup/:cgroup/docker/:container_id
Systemd: /sys/fs/cgroup/:cgroup/system.slice/docker-#{id}.scope
Then, to get the network usage of a container, the network namespace has to be entered thanks to the system call setns(fd). The fd parameter comes from a file handler of the file /proc/:pid/ns/net. After calling this function, the current process is in the same network namespace of the container, and standard tools car be used to see the consumed network bandwidth. (ie. read /proc/net/dev)
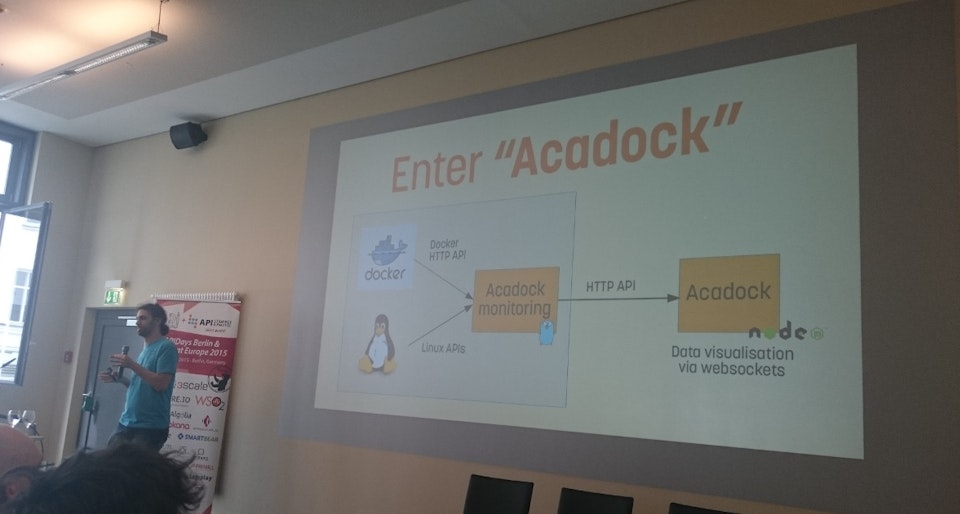
We’ve released the open-source daemon Acadock which exposes all the different data from the control groups and namespaces as a simple HTTP API. Additionaly it computes CPU percentage and network consumption over time. Obviously, you can configure it to have a lower refresh time than a second, have a look at the README.md for more information. The code is available on Github. Give it a try.
You can expect in the following months to be able to read resource usage data from our API, and of course on our web dashboard. With all these metrics you’ll be able to make the right decisions about your application containers like choosing the right number or the right size for them.
The slides from the presentation are also available:
– Léo Unbekandt, CTO at Scalingo





