Docker Image Building Strategy and The Fantasy of Image Size Reduction

At Scalingo, we’re using Docker as a core tool of our infrastructure. We’ve bet on it since its early days to build this PaaS. Our customers send their code, we transform it to a Docker image, which is executed in our infrastructure. We’ve read quite often that optimizing the size of Docker images is a kind of Holy Grail everyone should respect. That’s sometimes true, and sometimes it’s not. When you’re building numerous different images, you’ll be pretty happy to have them sharing a common base. This article will explain how we’re using Docker images and how, in one case, it is useful to think about the size of an image, and sometimes it’s not.
Scalingo’s Context
We are using Docker containers at two different steps of the workflow we’re proposing. First comes the build step. A container is created, your code and all its dependencies are gathered thanks to the buildpacks, resulting finally in a Docker image, stored in a private highly available registry hosted in our infrastructure. Each time, our orchestrator sends a request to start a container of your application, one or multiple servers of our infrastructure get the image we’ve previously built and run it, that’s the run step.
In this case, we’ve covered what we called application images , images which are dynamically built according to the deployed app. We’re also handling another type of images: database images , pre-built image to run the different types of database handled by the platform: MySQL, PostgreSQL, MongoDB, Redis, Elasticsearch.
Structure of application images
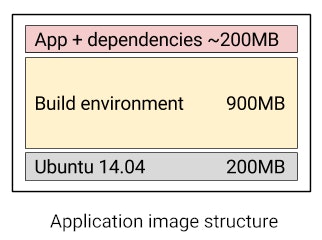
When an application is deployed, we create a container based on what we’ve called a builder image , this image is open-source and you’ll find it in the Docker Hub, named scalingo/builder. Each time any user deploys a new release of their application, a container is created based on this builder image. Once the build of the app and its dependencies is done, another unique layer is added to the image resulting to the application image. As soon as the image is sent to the registry, this last layer only is sent as all the others layers are common.
The builder image is a common base to all the applications hosted on the platform, as a result, it should be a generic image which is unspecialized. That’s why it is based on a stable Ubuntu LTS environment (currently 14.04 LTS).
In this builder image, we’ve installed different libraries and softwares which are commonly used, in the build process of application or to be used by a human when running one-off containers. You’ll find:
- Build essential utility (GCC, make, autotools and more.)
- curl, git, telnet, ssh-client, openssl
- NodeJS, Ruby, Perl, Python, Java (system version, nothing specific to app)
- Imagemagicks
- MySQL, PostgreSQL, MongoDB, Redis clients and development librairies
Making these default libraries and softwares optional has been part of our reflexion. We know that all application won’t use imagemagicks for instance, but we’ve considered that managing a set of builder images instead of one is not worth it. Actually, a common question asked is: “why are you using a unique image instead of multiple images based on the technology of the application, wouldn’t it speed the deployment process?”
Moving one image all around a cluster is much easier and convenient than handling myriad of images. Even if we sacrifice a few megabytes of disk space for this precise image. Once it has been fetched on a hosting node, we’re done. When a new application has to start, the application layer is fetched and nothing else. It contains everything required to run the contained application. As an example, imagine we want to create a specialized image for ruby applications, we should be maintaining the images for all versions of ruby since 1.8.7, it would represent more or less 30 images to prepare and maintain through the time.
People often argue about the size of Docker image, but in this case we’ve considered, having one common and large base image is the good way to go. There is no difference for us if the image is 800MB or 1000MB, servers get it once and use it thousands of times. Here is the schema of the structure of our builder image:
Database Images
With database images, we had another approach, as we control what will be running in the containers , we don’t need to build these images on a really generic stack, all it has to do is to run the database we’re looking for and do it well.
As well, we’re working with five types of database, each one having multiple versions , so to avoid filling our disks with database images, we’ve started looking at how to reduce their size significantly. In this field, Docker images based on Alpine Linux instead of Ubuntu or Debian seem to win the race.
Alpine Linux is a lightweight linux distribution weighing nothing more than 5MB. It is way less than the standard Ubuntu image, which is, as we’ve seen in the schema, 200MB heavy.
As a result, our redis image is now weighing 14MB. Previously, we never took care of the image size, it was 364MB large. Reducing the size of an image by a factor of 30× without loosing any feature of what the image should do, is definitely worth it. Working with such images gives us more flexibility are we’re able to migrate databases faster.
All our database Docker images are available on the Docker Hub, don’t hesitate to give them a shot.
Conclusion
As you can see, reducing Docker image size can be useful sometimes. However, it’s not THE ultimate goal you should reach first. Especially if you’re building multiple Docker images containing different applications under heavy development. Learn more about our Docker Image Building as a Service at build.scalingo.com.