7 min read
Introducing LinK, a virtual IP manager backed by etcd
We've just open sourced LinK, our virtual IP manager.

LinK (LinK is not Keepalived) is a virtual IP manager to help achieving high availability. It aims to simplify the share of a single IP between multiple hosts. We open source this tool today under the MIT license so that anybody can use it, and is free to contribute.
We introduced Software Defined Networks (SDN) into our infrastructure thanks to both LinK and SAND while working on highly available on-demand Elasticsearch clusters service on Scalingo (SAND will be introduced in a following article).
LinK is a networking agent that will let multiple hosts share a virtual IP. It chooses which host must bind this virtual IP and inform other members of the network of the host owning it. A typical use case is when you have a couple of proxies in front of a cluster. One is the master and the other is just here in case of trouble with the master. This failover proxy binds the virtual IP if the current master is detected as faulty so that the cluster keeps being reachable.
If you'd like to go read the source directly, LinK source code lies in this GitHub repository.
The Objectives
We had several objectives before starting the development of this software. First, no central controller should centralize the information. When dealing with highly distributed environment, you want to limit the communication as much as possible. Having autonomous agent knowing how to react in case of networking issue is a big pro. Hence, the architecture of LinK should be: one agent per host and that's it! No central controller.
Another strong objective is to always have at least one server binding the virtual IP. Indeed, this IP is used for highly available setup, hence it should always be reachable. At a given time, two hosts possibly bind the virtual IP. This is perfectly fine as it does not prevent the virtual IP to be reachable by someone.
Last but not least, we want to follow UNIX philosophy: "Do one thing and do it well". LinK is only responsible for the IP attribution part. It will not manage load balancing or other higher level stuff.
Why not using Keepalived?
We are already using Keepalived for some of our internal components (DNS, load balancers, etc.) and we first wanted to use it for this IP failover mechanism. But while specifying this we faced some limitations of Keepalived.
The most prominent limitation is the amount of IP scheduler Keepalived allows. In our setup, each database needs its own virtual IP scheduler. With Keepalived, you need to specify a different virtual_router_id in the vrrp_instance section. As the virtual_router_id is coded on a single byte in the VRRP protocol we would only have 256 virtual IP scheduler on our entire infrastructure. This is not acceptable since it would limit us to host less than 256 clusters. Some others architectures were considered but each of them had some significant drawbacks.
When working on this issue we looked at how the IP sharing worked on Keepalived and saw that it was pretty simple. The complexity of Keepalived comes from the IP scheduling (determine which node must have the IP). In Keepalived this is done thanks to the VRRP protocol. However, at Scalingo we already have a distributed component that know how to manage elections and leases: etcd. Finally, as a bonus, if we create our own virtual IP manager, we would be able to control it via a REST API. This is way simpler than modifying configuration files on the disk!
LinK Architecture
The idea of LinK architecture is to have an agent on every host which could potentially bind the IP. Here is a global overview of an infrastructure running LinK:
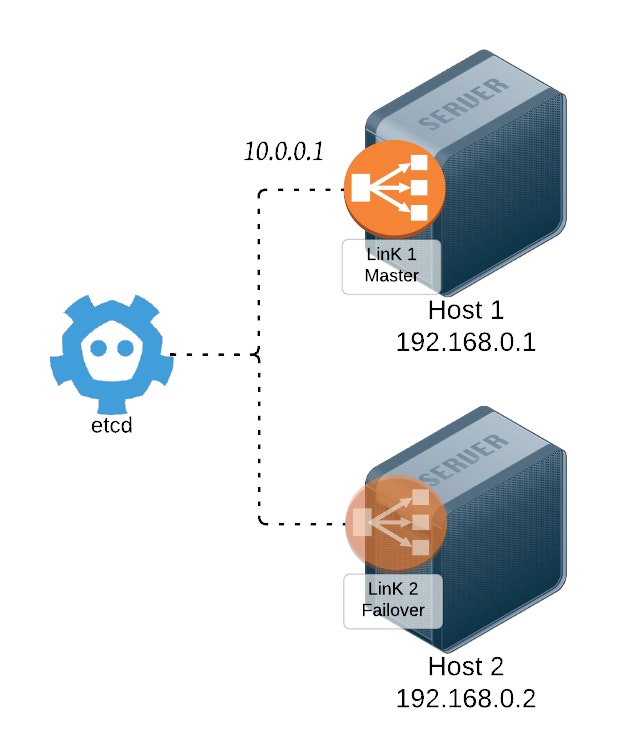
Each host has an IP (in 192.168.0.0/16 range on the sample) and runs a LinK agent. All the agents can bind the virtual IP (in 10.0.0.0/8 range). Etcd is reachable for all the hosts. Note that we only represented two hosts but more hosts can join this LinK network of agents.
Each of the agents runs the following state machine:
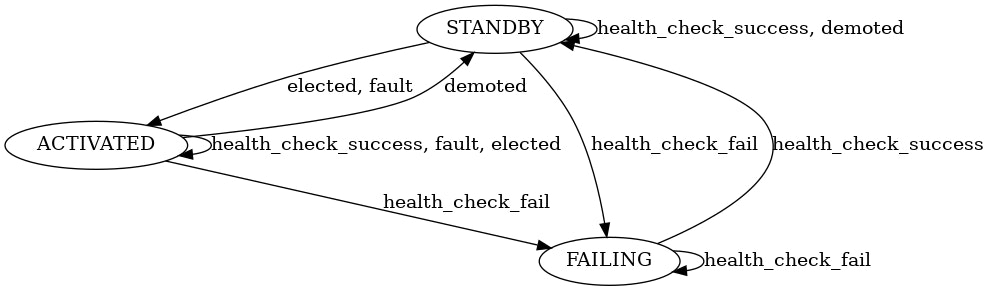
It has three different states: - ACTIVATED: this agent binds the virtual IP, - STANDBY: this agent does not own the virtual IP but is available for election, - FAILING: health checks for this host failed, this agent is not available for election.
And various events can occur. These events would modify the state of the agent: - fault: there was some error when coordinating with other nodes, - elected: this agent was elected to bind the virtual IP, - demoted: this agent just lost ownership of the virtual IP, - health_check_fail: the health checks configured failed, - health_check_success: the health checks configured succeeded.
The health checks are configurable. It is a method to detect that a host is failing and should not bind the IP. Currently the LinK agent uses a TCP connection to the host running it in order to detect a failure.
With this state machine in place, every agent can autonomously knows which state it is in. There is a possibility that two different agents are in the ACTIVATED state. LinK is designed to handle such a situation. It is not a problem and the hosts trying to connect to the virtual IP will end up using one of these hosts.
One missing piece is how to synchronize the LinK agents without using a central controller. Our solution is to use etcd, a distributed key/value store.
Agents Synchronization
The hosts can detect they need to bind the IP thanks to etcd. LinK agents use the etcd lease feature: a lock mechanism with a timeout. All LinK agents try to take the lock. The one which succeeds to take it have the lock for 6 seconds hence binds the virtual IP during this period. Every 3 seconds, it tries to refresh the lease (i.e. extend the lock for 6 seconds). If it fails to refresh the lease, another agent will get the lease and binds the virtual IP.
The last small issue we need to fix is ARP (Address Resolution Protocol) cache invalidation. How to ensure that all the hosts in the local network are aware of the new host binding the virtual IP?
A Bit of Theory About ARP
ARP has originally been designed as the glue between the Ethernet and the IP protocols. In a local network, when a host wants to communicate with another host but only has the destination IP address, it needs to discover the destination MAC address. The mechanism to do so is to broadcast an ARP request, asking for the MAC address matching the given IP. In order to speedup this process, every host keeps a cache of the pairs IP / MAC addresses. This ARP cache has a short TTL.
On our sample infrastructure, if any host wants to communicate with Host 1 on its IP address 192.168.0.1, it sends an ARP request to all hosts in the local network asking for the MAC address of 192.168.0.1. The Host 1 would reply with its MAC address, let's say MAC 1.
Back to the LinK situation, if Host 1 binds the virtual IP 10.0.0.1 and another host (Host 3) tries to communicate with it, Host 1 will answer MAC 1 to the ARP request. A bit later, Host 2 gets the etcd lease and binds the virtual IP 10.0.0.1. Host 3 has an entry in its ARP cache for the IP address 10.0.0.1 and sends the message to MAC 1 whereas Host 2 binds the IP.
This is solved by using gratuitous ARP request. When an agent binds the IP, it broadcasts a gratuitous ARP request where the source and destination IP are set to the virtual IP and the source Ethernet is the agent's host Ethernet address. Hence, all hosts in the same network are aware that the IP address is owned by a specific agent which invalidates there cache.
We devised LinK to ensure failover mechanism between the two front HAProxy for database clusters. LinK is now open source as we are convinced that a clean, simple, fault tolerant and highly distributed virtual IP manager can benefit to many of you out there. We will keep using it and working on it internally. External contributions are more than welcome, we do accept pull requests. Feel free to use it, LinK source code is available in this GitHub repository.
Photo by Fabio Ballasina on Unsplash

Jonathan Hurter
Jonathan was one of the first developer at Scalingo. He started to work for Scalingo in 2016 and from time to time he also writes blog article. On the side he is very active in the associative life of Strasbourg and was a code teacher for some time.
Stay Updated
Get articles and platform updates in your inbox.
Ready to Deploy with Confidence?
Experience zero-downtime deployments, intelligent auto-scaling, and fully managed infrastructure. Start deploying your applications on Scalingo today.
No credit card required • Deploy in minutes • Cancel anytime






