10 min read
Autoscaling: automagically scale your application based on your application metrics
Autoscaling feature is made globally available on Scalingo!

Today we announce the general availability (GA) of the long-awaited autoscaling feature for your containers!
This feature has been available upon request for the past 18 months, and we are now 100% confident about it.
As of today, it is made globally available!
In this short article we will explain what is autoscaling and how it can simplify your life in your company.
What is autoscaling useful for?
You already know that Scalingo is great to scale your application in a minute. At a click range, you can scale your application from one to hundreds of containers!
The next step many of you have been expecting is autoscaling based on application metrics.
The typical use case scenario for this brand new autoscaling feature is a story we all heard about.
You developed a great application and wisely chose to host it on Scalingo.
At first your application is not widely used and you scale it on 2 containers.
Without notifying you upfront, someone post your application on Hacker News front page and your app becomes suddenly overloaded by user requests.
Your application crashes as you didn't planned to get that much requests. All these potential customers will never be able to reach your application. By the time you manually scale up your application, the traffic peak is over and your resource consumption is back to normal.
Thanks to the autoscaling feature, you can setup a target on one of your application metric, so that the autoscaler will automagically scale up and down the application in order to keep the metric as close to the target as possible.
How to setup an Autoscaler for your Application?
The autoscaler is configurable per container type through the Scalingo dashboard, in the Resources section. Click on the down arrow near the Scale button, and configure the autoscaler for any container type you want:
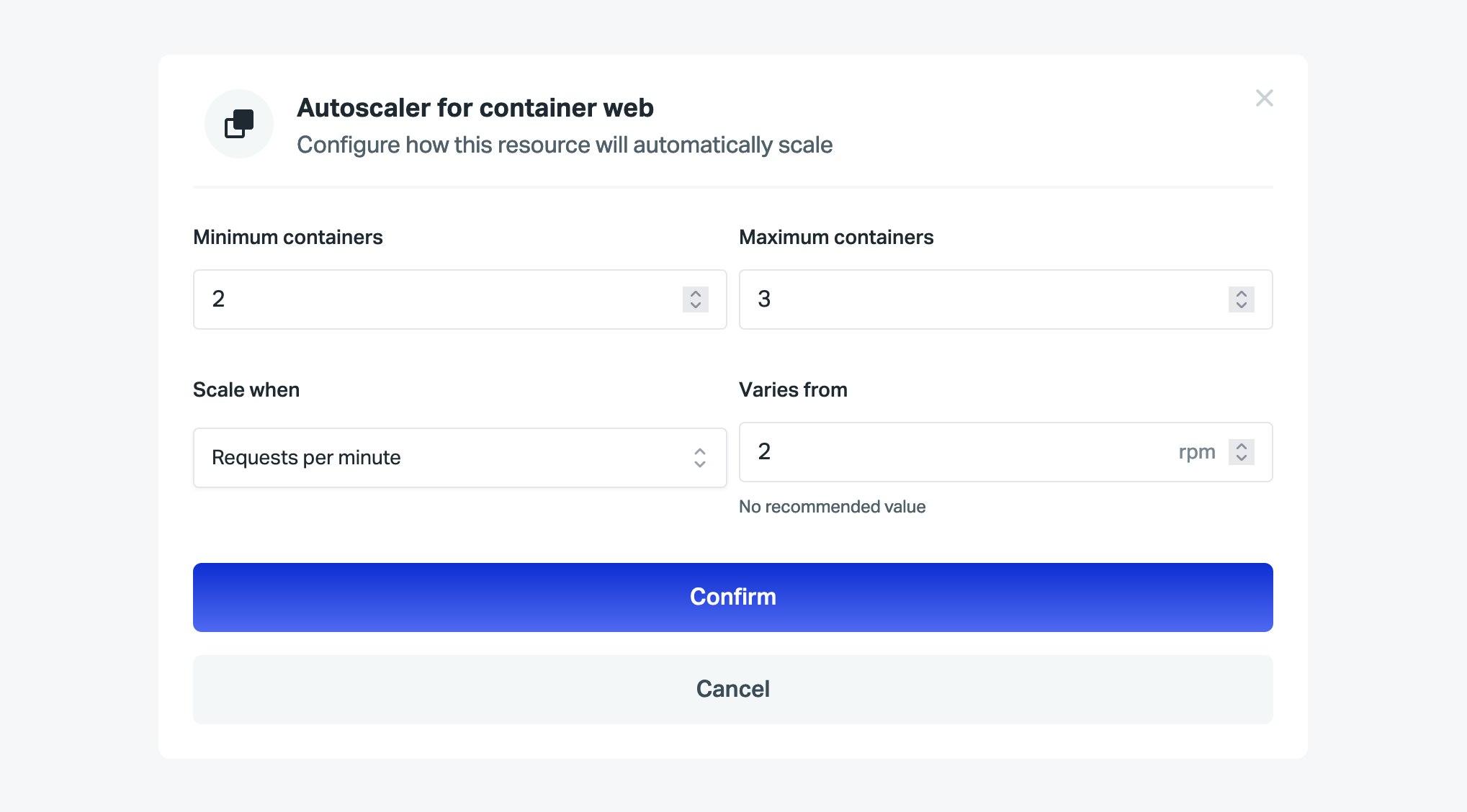
Autoscaler can use the following metrics:
CPU, RAM and swap: percentage of this resource consumption
Response time: 95th percentile of the requests response time
RPM and RPM per container: requests per minute (RPM) received by your application. The RPM per container metric divides the RPM of the application by the amount of containers.
Note that non-web containers can only use CPU, RAM and swap to define an autoscaler.
We also provide you with recommended value that you can use as a target. It is 90% of the maximum allocated to your application for CPU and RAM, 10% of the maximum allocated to your application for swap, and the median over the last 24 hours for the other metrics.
The autoscaler only scales the application up or down by one container. After a scale up event, the autoscaler will not scale the application up again before at least one minute.
The scale down is a bit less aggressive. Indeed we define the scale down threshold to 20% below the defined target value. After a scale down event, the autoscaler will not scale the application down before at least three minutes. These cooldown values prevent the autoscaler to scale the application frantically.
Autoscaling Related Events
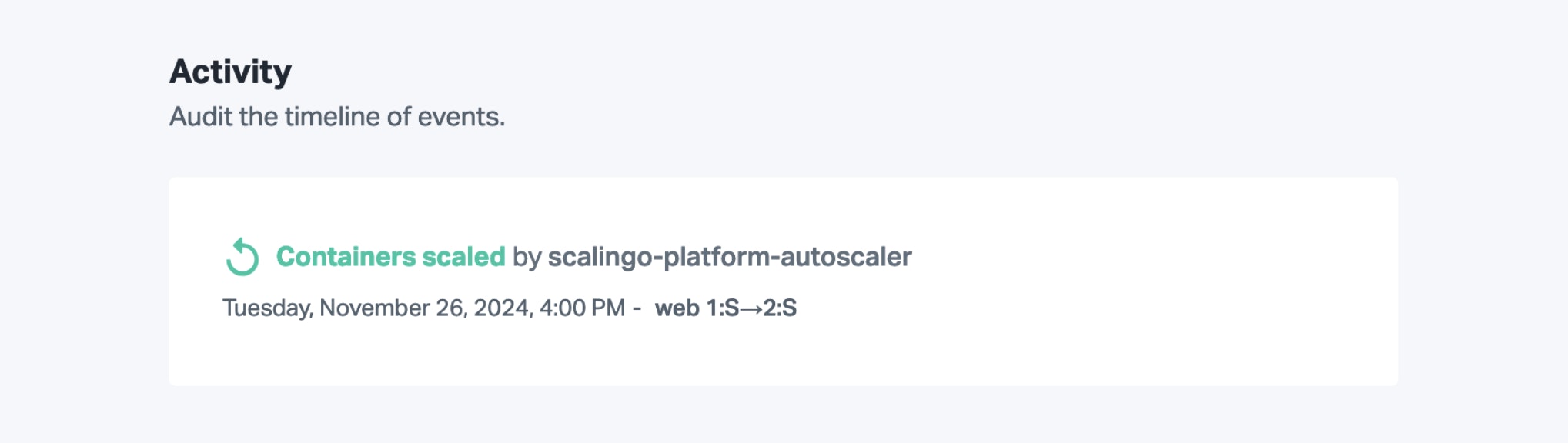
An event is generated when an autoscaler is created or updated:

Every time an autoscaling decision is done, an event is also created. This event appears on the application's timeline. The user responsible for the operation is labeled scalingo-platform-autoscaler:
How Does the Autoscaling Work?
In order to keep the metric as close to the target as possible, we designed a threshold-based algorithm. To detect that a scale up or down is needed, we take an average of the metric on the last 5 minutes and compare it with two limits. The value associated to these limits depends on the metric you chose for your autoscaler and the defined target.
RPM per Container
The RPM per container metric is well suited if you know your application for a long time and know that it works well if it receives a certain amount of requests per container. The limit above which the application will be scaled up is:
The limit below which the application will be scaled down is:
Here is the typical scenario which explains this choice.
Let's say a user defines the target to 100 RPM per container. The application has 5 containers and receives 500 RPM. The limit to scale up is 120 and the scale down limit is 80.
Suddenly the application receives 1000 RPM. The RPM per container is 200 (above the 120 scale up limit). We scale the application up to 6 containers. The scale up limit becomes 117. We keep scaling the application up to 9 containers. The RPM per container is now 111 and the scale up limit is 111. The scale down limit is 89.
Then the RPM drops to 500. The RPM per container is 56. We scale down the application to 8. The RPM per container is 63 and the scale down limit is 87.5.
We keep scaling down the application to 6 where the down limit and the RPM per container equals 83.
With this algorithm, we are able to keep the actual RPM per container as close to the target as possible without scaling up and down the application too frantically. We believe this metric along with this algorithm suits most of the needs of a typical web application.
Resource Consumption
Another type of metrics you may need is based on the resources consumption of your application (i.e. CPU, RAM or swap). For instance, you don't want your application to starve from RAM exhaustion.
You can define the target to 80%. The limit to scale the application up equals the target. Hence whenever your application consumes more than 80% of RAM, it scales up to spread the load amongst more containers. The limit to scale the application down is:
Other Metrics
For the other metrics, the limits formulae are:
Autoscaling Limits
The autoscaler is not a magical solution which solves every scaling problem. In order to prevent the autoscaler to over-react, we added delays and cooldown which induce a lower reaction time. It may take a bit of time to fully kick in and it won't absorb a sudden, high peak.
Moreover, an increased response time or resource consumption of an application can have different causes and scaling horizontally might not solve the issue. These causes can be:
A memory leak in your application.
The database uses all its resources.
In such cases, configuring an autoscaler will not improve the responsiveness of the application. One should investigate these issues before enabling an autoscaler.
Conclusion
Many of you asked for the autoscaling feature and we are very proud to make it generally available today. Feel free to add one to your application to add another safety net to your application.
Banner image by Dan Meyers on Unsplash

Étienne Michon
Étienne Michon was one of Scalingo's first employees. With a PhD in computer science, Étienne takes care of Research and Development at Scalingo. He also regularly contributes to this blog with technical articles.
Stay Updated
Get articles and platform updates in your inbox.
Ready to Deploy with Confidence?
Experience zero-downtime deployments, intelligent auto-scaling, and fully managed infrastructure. Start deploying your applications on Scalingo today.
No credit card required • Deploy in minutes • Cancel anytime




