7 min read
Scalingo PostgreSQL clusters with<br/> hot standby, PITR and more
We are happy to announce that PostgreSQL clusters are now available on Scalingo with new capabilities to Scalingo PostgreSQL.

We are happy to announce that PostgreSQL clusters are now available on Scalingo, adding high availability to our current single node offering and introducing new capabilities to Scalingo PostgreSQL.
PostgreSQL Clusters on Scalingo
When you provision a PostgreSQL cluster on Scalingo, we start two PostgreSQL nodes. One of the node is designated the leader and the other is the follower. Whenever a data is inserted on the leader, it is immediately replicated on the follower. Thanks to this replication setup, if a node fails for whatever reason, your database will still be accessible, with a short downtime.
From the client's point of view (usually your application) there's a single entry point to the cluster, called the gateway, which takes care of the load balancing between all the nodes of the cluster. Thus the environment variable injected into the context of your application still contains a single domain name:
postgres://<username>:<password>@dbhost.scalingo.com:12345/<dbname>.
TLS Everywhere
As usual, the security of the communication to the database and between the cluster members is top priority for us. We added TLS for all level of communications:
from the application to the gateway,
from the gateway to the leader,
from the leader to the follower,
between the cluster orchestrator (Patroni) and its database (etcd)
Moreover, by default your database is not reachable from outside Scalingo's network. To make it reachable from anywhere around the world, you first need to force TLS communication to connect to the PostgreSQL cluster.
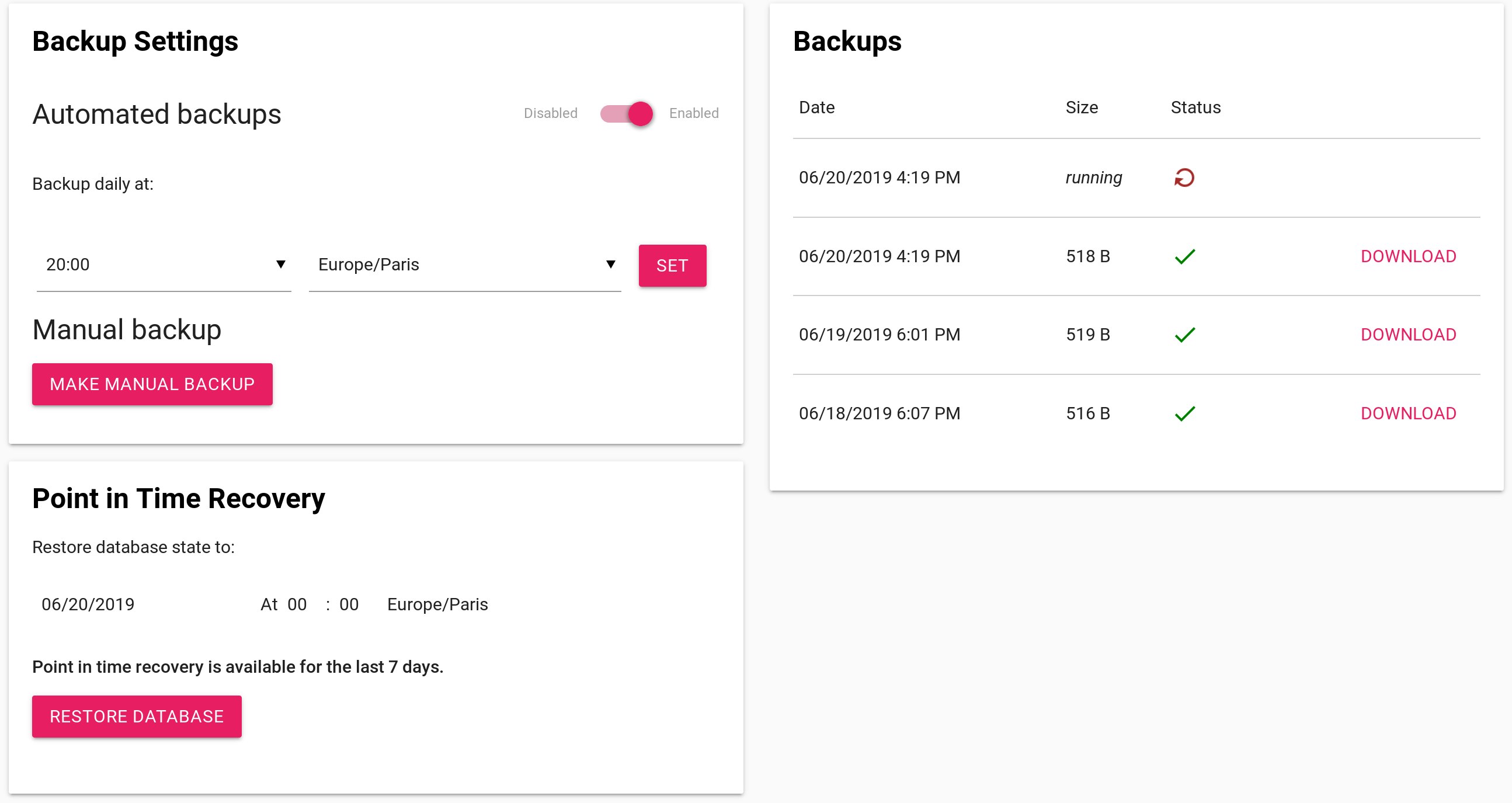
New Backups Settings
With this new setup, we are able to offer two ways of backing up the data of your database.
On-Demand Backups
You can ask the platform for a backup which will be performed on the follower node (if on a Business plan, on the leader node otherwise) using the standard tool pg_dump. It makes a full backup of your database and outputs a series of SQL commands you can execute to get a copy of the database at the state when the backup was done.
On-demand backups are performed asynchronously. You can list them with the web dashboard, the CLI or the API. They are limited in total number and maximum number per day. For example, if your plan allows for 15 backups total and you already have asked for 15 on-demand backups, the next time you ask for one, your oldest on-demand backup will be deleted.
On-demand backups can be automated on a daily basis. You can specify your preferred time of the day when the backup will be triggered.
Point-in-Time Recovery aka PITR
We added a new way to backup PostgreSQL data which allows to do Point-in-Time Recovery (PITR). We use the tool pgBackRest to achieve this. We make a full PITR backup of the database weekly, and between two PITR backups, we keep track of the write-ahead logs (WAL). The WAL contains all the modification instructions. By replaying the WAL from a PITR backup to a specific date, we are able to rebuild the state of the database at that date.
PITR ensures strong durability of your data.
Here is the update on your database dashboard to highlight those two novelties:
Update to the Version Upgrade Procedure
The procedure to do a version upgrade of your cluster is almost identical. We first need to stop all database nodes before executing pg_upgrade on the leader data. Then the nodes are restarted using the new major version.
When the primary node is completely started, it is time to update the extensions you activated. Last but not least, it is mandatory to take a new PITR backup. The one taken on the previous major version is incompatible with the new version. It has an important side effect: it is impossible to use a date prior to the major upgrade for a point-in-time recovery.
Note that we are still working on a better way to implement the upgrade of a major version of PostgreSQL which reduces the downtime of your database.
How to Take Advantage of PostgreSQL High Availability?
This feature is available as part of new plans for your database. If you start a new database, you will be prompted to choose a plan. All the Business plans include cluster with three nodes holding the data and two gateway nodes. The first cluster ready version is 10.9-1. It is the 1st Scalingo revision of the version 10.9 of PostgreSQL.
For an existing database, getting a cluster takes a few steps. First, upgrade to the latest 10.9-1 version. It will start your database with a mono-node setup (i.e. a PostgreSQL instance in its own private network with a single gateway). Then you can change the plan in the "Addons" section of your application to choose a Business plan. Your database will migrate seamlessly from a mono-node setup to a highly available setup.
After upgrading your plan to a Business plan, your database is highly available and Scalingo ensures a 99.99% availability of your database. Moreover, updating to a more recent version is achieved with very limited downtime see the section above section about "version upgrade procedure".
You don't have to worry about data portability: your PostgreSQL database is completely standard (the base Docker images are open source) and you can retrieve all your data by querying it or download a backup.
New Pricing Grid Introducing Business Plans
Former mono-node plans are now available under the new plans category Starter while the old Free tier is now available under the name Sandbox.
There are 3 pricing categories:
Sandbox contains only 1 plan and should only be used for development purposes. No SLA is offered on this plan.
Starter plans offers mono-node cluster deployment (no high availability) but all of them includes automatic daily backups.
Business plans are the ones you're looking for if you're doing production stuff: cluster all the way and improved availability.
You'll find the new pricing grid below:
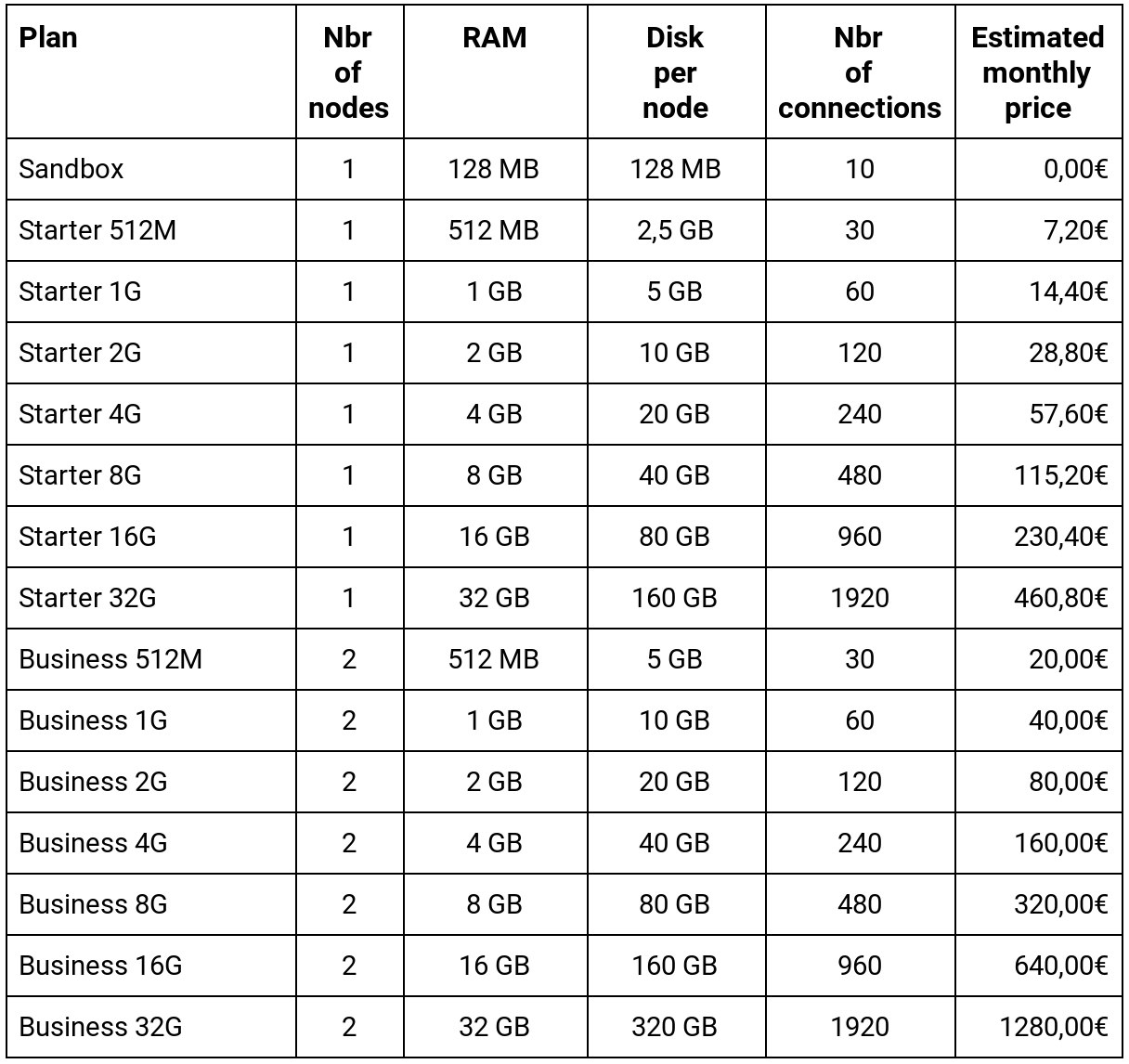
As of today, all old plans are renamed with the prefix "Starter" and "Free tier" is renamed "Sandbox".
If you have questions or remarks regarding the new pricing plans or the new cluster feature, don't hesitate to contact us. We'd love to hear your feedbacks!
Technical aspects
In order to get PostgreSQL clusters running magically, we benefited from the work done along with Elasticsearch cluster and Redis cluster. Here is the network setup for PostgreSQL cluster:
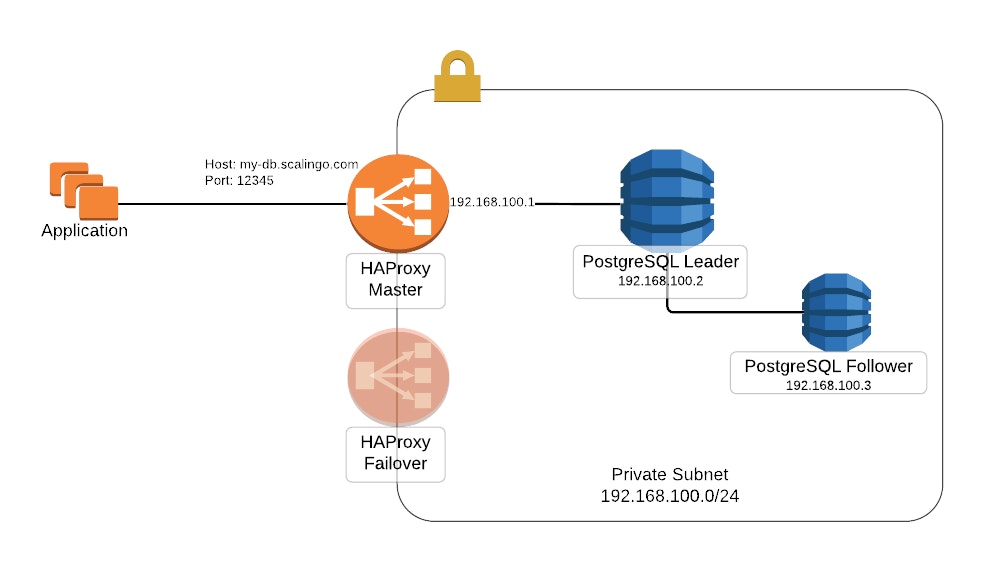
When your application queries the PostgreSQL database, it enters the private network through a unique entry point, called Gateway internally, forwarding the requests to the PostgreSQL leader. To prevent this gateway to be a single point of failure, a second one is started as a failover in case the first one is down. We ensure the failover mechanism with LinK, a virtual IP manager. Currently, those gateways are HAProxy servers.
To increase the security of your cluster, nodes are booted in a dedicated private network based on VXLAN with the help of SAND, an autonomous service managing overlay networks.
Even though PostgreSQL embeds some mechanism to ensure replication, hence a high availability setup, it is easier to use a software such as Patroni to setup a high availability PostgreSQL cluster. Patroni, formerly know as Governor, is a template we used to simplify the task of setting up high availability with PostgreSQL. It adds a HTTP API to modify PostgreSQL configuration without needing to restart the instance (for most parameters). It also ease the task of setting up a point-in-time recovery of the database.
Photo by Maxim Medvedev on Unsplash

Étienne Michon
Étienne Michon was one of Scalingo's first employees. With a PhD in computer science, Étienne takes care of Research and Development at Scalingo. He also regularly contributes to this blog with technical articles.
Stay Updated
Get articles and platform updates in your inbox.
Ready to Deploy with Confidence?
Experience zero-downtime deployments, intelligent auto-scaling, and fully managed infrastructure. Start deploying your applications on Scalingo today.
No credit card required • Deploy in minutes • Cancel anytime





